
こんにちは。田原です。
オブジェクト指向プログラミングの3大特長は、「隠蔽」、「継承」、「動的なポリモーフィズム」です。前回はデータとアルゴリズムをセットにすることで外部から「隠蔽」し、クラス変更の影響を最小限にすることを解説しました。
今回はそのクラスを他のクラスへ「継承」する機能について解説します。サブルーチンより遥かに強力です。
「継承」はあるクラスが他のクラスの機能をほぼ丸ごと取り込む(継承する)仕組みです。
次のように記述して継承します。(DerivedクラスがBaseクラスを継承してます。)
// 通常のクラス定義
class Base
{
// 各種メンバの定義
};
// Baseクラスを継承したDerivedクラスの定義
class Derived : public Base
{
// 各種メンバの定義
};
継承により引き継ぐことができるものは、原則としてprivateでないBaseクラスの全てのメンバです。全ての非staticメンバ変数、非staticメンバ関数、staticメンバ変数、staticメンバ関数です。(staticメンバ変数、staticメンバ関数についてはもう少し先で解説します。)
ただし、一部のメンバ関数はprivateでなくても自動的には継承されません。この後の「2.手動で引き継ぎ(using)」で詳しく説明します。
ここでちょっと用語について書いておきます。
継承関係については、「DerivedクラスはBaseクラスを継承している」、「BaseクラスからDerivedクラスを派生している」などと表現します。
また、それぞれのクラスについては、呼び方が多数あります。次のような表現を良く聞きます。
Baseクラス 基底クラス、基本クラス、ベース・クラス、スーパー・クラス、親クラス Derivedクラス 派生クラス、サブ・クラス、子クラス 当講座では主に、基底クラス/派生クラスを使います。
#include<iostream>
class Base
{
public:
int mBaseVar;
void BaseFunc() { std::cout << "BaseFunc()\n"; }
Base() : mBaseVar(10) { }
};
class Derived : public Base
{
public:
int mDerivedVar;
Derived() : mDerivedVar(100) { }
void DerivedFunc()
{
std::cout << "mBaseVar+mDerivedVar= " << mBaseVar+mDerivedVar<< "\n";
}
};
int main()
{
Derived derived;
derived.BaseFunc();
std::cout << "derived.mBaseVar = " << derived.mBaseVar << "\n";
std::cout << "derived.mDerivedVar = " << derived.mDerivedVar << "\n";
derived.DerivedFunc();
}
まず、派生クラスのDerivedFunc()の中で基底クラスのmBaseVarをまるで自分のメンバ変数であるかのようにアクセスしています。(もちろん設定も可能です。)
そして、基底クラス(Base)のmBaseVarとBaseFunc()がまるで派生クラス(Derived)が提供しているかのように見えています。
このように継承したクラスの非privateメンバを全て自分のものとし、更にpublicであればそのまま外部へ公開することができます。更にオーバーライド(override)等の仕組みを使って仕様を変えて公開することさえできます。
前節のDerivedクラスのインスタンスは次のようなメモリ配置になります。

ちょっと簡単すぎて説明し辛いので、ほんの少し複雑にしてみます。
#include<iostream>
class Base
{
public:
int mBaseVar0;
int mBaseVar1;
Base() : mBaseVar0(10), mBaseVar1(11) { }
};
class Derived : public Base
{
public:
int mDerivedVar0;
int mDerivedVar1;
Derived() : mDerivedVar0(100), mDerivedVar1(101) { }
};
int main()
{
Derived derived;
std::cout << "&derived = " << &derived << "\n";
std::cout << "&derived.mBaseVar0 = " << &derived.mBaseVar0 << "\n";
std::cout << "&derived.mBaseVar1 = " << &derived.mBaseVar1 << "\n";
std::cout << "&derived.mDerivedVar0 = " << &derived.mDerivedVar0 << "\n";
std::cout << "&derived.mDerivedVar1 = " << &derived.mDerivedVar1 << "\n";
}
&derived = 004FF6F8 &derived.mBaseVar0 = 004FF6F8 &derived.mBaseVar1 = 004FF6FC &derived.mDerivedVar0 = 004FF700 &derived.mDerivedVar1 = 004FF704
&derived = 0x7ffe2ea1d9e0 &derived.mBaseVar0 = 0x7ffe2ea1d9e0 &derived.mBaseVar1 = 0x7ffe2ea1d9e4 &derived.mDerivedVar0 = 0x7ffe2ea1d9e8 &derived.mDerivedVar1 = 0x7ffe2ea1d9ec
Visual C++の例を図で表すと次のようになります。(なお、アドレスは実行する度に変化しますので、皆さんのところで実行した場合とアドレスは異なります。)
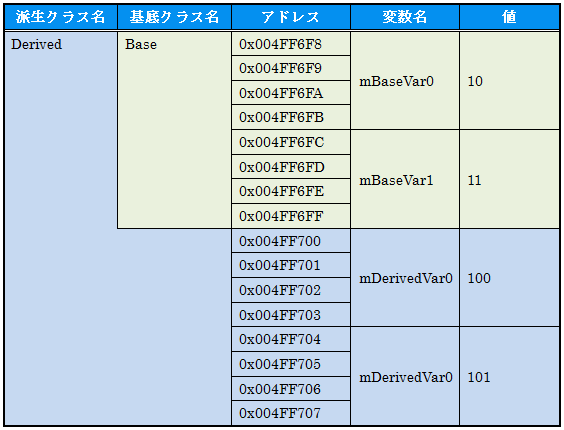
このように基底クラスは派生クラスの中にそのままの姿で配置されます。
この特性により、Derivedクラス変数へのポインタをBaseクラスへのポインタbase_ptrへ変換した場合、base_ptrを使ってmBaseVar0とmBaseVar1にアクセスできます。
Derived derived;
Base* base_ptr=&derived;
std::cout << "base_ptr->mBaseVar0 = " << base_ptr->mBaseVar0 << "\n";
std::cout << "base_ptr->mBaseVar1 = " << base_ptr->mBaseVar1 << "\n";
// std::cout << "base_ptr->mDerivedVar0= " << base_ptr->mDerivedVar0 << "\n"; // error!
なお、ある意味当然なのですが、mDerivedVar0とmDerivedVar1はBaseクラスのデータの後に続いて存在していますが、Baseクラス自体ははDerivedクラスの情報を持っていません。なので、Baseクラスへのポインタbase_ptrを使ってmDerivedVar0とmDerivedVar1へアクセスすることはでません。
基底クラスへのポインタを使って派生クラスのメンバにアクセスできない
実は、C言語的な使い方をすれば可能です。どのようなメモリ配置になるのか把握して、適切な演算を施せば可能なのです。今回の場合は、Derivedクラスへの追加したものはBaseクラスの中身と同じint型2つですから、(base_ptr+1)->mBaseVar0は、derived.mDerivedVar0と記憶領域が一致します。
ですのでアクセスは可能です。しかし、これはプログラマが非常に注意深くプログラムすることで適正にアクセスできる方法です。多量の注意力が必要になります。折角C++を使うのであればそのようなことはせず、C++にメモリ管理を任せてC++にできるだけバグ検出させるようなコーディングをお勧めします。
派生クラスは基底クラスを含んでいるので、派生クラス変数へのポインタを基底クラスへのポインタへ変換しても危険はありません。
しかし、逆はまずいです。基底クラスは派生クラスを含んでいませんから、基底クラス変数へのポインタを派生クラスのポインタへ設定すると派生クラス側のメンバ変数の記憶領域が存在しないため異常動作します。
Base base;
// Derived* derived_ptr=&base; // Error
Derived* derived_ptr=reinterpret_cast<Derived*>(&base);
derived_ptr->mDerivedVar0=200;
derived_ptr->mDerivedVar1=201;
派生クラスへのポインタへ基底クラスへのポインタを設定しようとした時点でコンパイル・エラーになります。しかし、後日解説するキャストを使って無理やり代入させることが可能です。その場合、運が良ければmDerivedVar0メンバ変数等への代入で落ちます。運が悪いと他のメモリを破壊します。どこのメモリが破壊されるのか見つけるのは至難の技です。
他のクラスを継承するということは、そのクラスの機能を自分のものにするという意味でした。
では、継承できるクラスは一つしか無いのですか?という疑問が生じると思います。
例えば、日本舞踊とお茶と陶芸のお師匠様に師事してそれらの技術を継承することは難易度は高いですが、不可能な話ではないでしょう。
C++も実は同じです。複数のクラスの機能を継承することは可能です。ただし、それを使いこなすことは難易度が結構高いです。
例えば、クラスA, B, C, Dがあり、次のように継承していたとします。
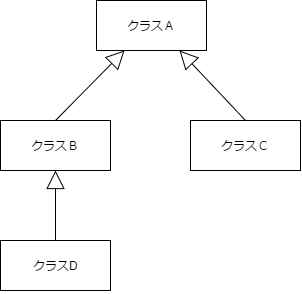
この時、メモリ配置は次のようになります。
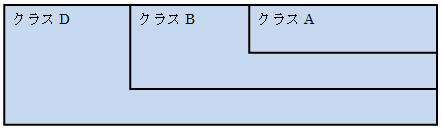
全ての継承関係にあるクラスはそれぞれ1つずつしか存在しませんので、難しい問題が発生しません。
例えば、クラスA, B, C, Dがあり、次のように継承していたとします。(ダイヤモンドのような形で継承しているため、ダイヤモンド継承や菱形継承と呼ばれます。)
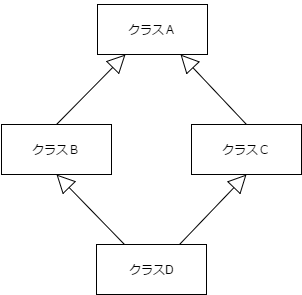
通常通りの継承の場合、メモリ配置は次のようになります。
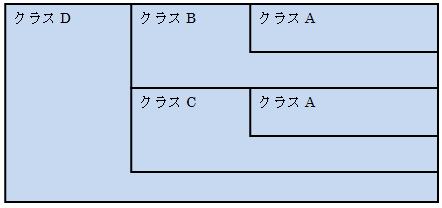
クラスAが2つあります。
クラスDからクラスAのメンバを使う場合、クラスBに属するものなのか、クラスCに属するものなのか指定する必要が有ります。
つまり、クラスAの機能を単純に継承するわけでなく、クラスBからの継承なのか、クラスCからの継承なのか意識してプログラムする必要があります。
ややこしいですね。正直、このような状態になった時、適切にプログラムする自信はあまりありません。
多重継承したからと言って、常にこのような継承をするとは限りませんが、よほど慎重に設計しないと直ぐにダイヤモンド継承になってしまいます。本質的に大本の基底クラスを1つに定めて、そこから次々と派生するような使い方がたいへん多いです。この時、大本の基底クラスは多数のクラスに継承されるため、多重継承によりダイヤモンドを形つくってしまうからです。
クラスAをクラスB, Cへ継承する際に特殊な方法(仮想継承)を用いることで、クラスAを共有できるようにすることも可能です。
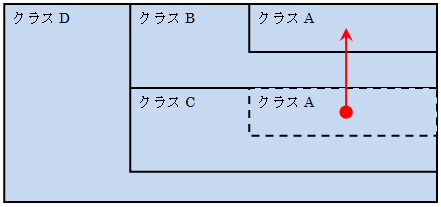
これなら、複数のクラスAを制御する必要がないので混乱しにくいように見えます。
しかし、クラスB側のメンバ関数を呼び出すことでクラスAの値が変わることがあります。
その変化をクラスC側は掴めません。気がついたら変わっているという事態が発生します。
つまり、クラスB、クラスCを開発する際、クラスAの値がいつの間に変化する可能性を考慮しておく必要があります。
こちらの場合のプログラミングの難易度は相当高いと感じます。通常継承の方がまだましでしょう。
このようにプログラミングが難しくなりがちですので、多重継承はできるだけ避けることが望ましいです。
どうしても必要な時は、ダイヤモンド継承しないよう慎重に設計することをお勧めします。
後日詳しく解説しますが、C++は異なる引数リストを持つ同じ名前の関数を定義することができます。オーバーロード(overload)といいます。英語的には「荷物の載せすぎ」と言う意味ですが、プログラミング言語の文脈では多重定義という意味になります。同じものをたくさん定義すると言う意味ですね。
同じものと言いつつ、微妙に異なるため呼び分けることができます。
さて、派生クラス側で何かメンバ関数が定義されていた場合、それと同じ名前の関数は全て継承されません。また、コンストラクタは基底クラスと派生クラスで名前が異なるように見えますが、同じ「コンストラクタ」として解釈されるため、やはり自動的には継承されません。・・・①
実は、継承されないと言うよりは隠されると言った方が正しく、ハイディング(隠蔽)と言います。
ローカル変数の隠蔽について解説しましたが、これも同じ仕組みです。同じ名前ものはより身近な方が使われるという原理です。
さて、もう一つ後日詳しく解説しますが、C++のクラスは特殊メンバ関数と呼ばれる関数があります。コンストラクタと代入演算子、それにデストラクタです。これらについてはコンパイラが多くの場合、自動生成します。
そのため、これらを仮に一切定義していなくても、コンパイラが自動生成するため、①の条件を満たしてしまい、自動的には継承されません。(定義していたら当然①を満たすのでやはり継承されません。)
そのため、C++11より前のC++では、折角基底クラスに存在していても、プログラマが関数宣言を定義し、基底クラスへ中継するコードを一々書いてました。特にコンストラクタが多数あるクラスを派生した時は、本当に面倒でした。
しかし、C++11では、継承したいメンバの名前を指定することで継承できるようになりました。ありがたい話です。次のように記述します。
using 基底クラス名::基底クラスの継承したいメンバ名;
コンストラクタを指定する時は、「基底クラスの継承したいメンバ名」には基底クラス名(=コンストラクタ名)を書きます。派生クラス側では派生クラス名(=コンストラクタ名)に展開されますので安心して下さい。
これにより、オーバーロード(多重定義)された複数の関数をごっそり持ってきます。
もし、引数リストも全く同じ関数が派生クラス側で定義されていた場合は、派生クラス側のものが有効になります。
継承の使い方としては大きく2種類の考え方があります。
- 基底クラスにちょっと機能を追加した派生クラスを定義する
- 大きな派生クラスにある特定の機能を追加するために基底クラスを継承する
どちらの場合も規模の大小が異なるだけで使い方は同じです。後者の方は多重継承したくなることが多々あるかも知れません。ダイヤモンド継承にならないよう要注意です。
1.のサンプルを作ることは簡単ですので、1.の例を示します。
std::stringをお手軽に拡張します。
std::stringは実体化されたクラス・テンプレートなので実体化前のクラス・テンプレートで定義した方がより汎用的なのですが、クラス・テンプレートの解説を始めるとキリがないのて、普通のクラスとして扱います。実体化されたクラス・テンプレートは事実上クラスと同じものなのです。
文字列操作する時、文字列を区切り文字毎に切り出す処理を行うことは結構あります。
そのような処理を行う関数はsplit()関数と呼ばれます。しかし、何故かstd::stringはsplit()関数を持っていません。
そこで、簡単にsplit()機能を追加してみます。(実用にするには微妙ですが、サンプルですのでご勘弁。)
#ifndef STRING_SPLIT_H
#define STRING_SPLIT_H
#include <string>
class StringSplit : public std::string
{
public:
using std::string::string;
using std::string::operator=;
StringSplit split(char iSeparator)
{
StringSplit ret;
std::size_t pos=find(iSeparator);
if (pos == std::string::npos)
{
ret=std::move(*this);
return ret;
}
ret=substr(0, pos);
*this=substr(pos+1);
return ret;
}
operator bool() const
{
return !empty();
}
};
#endif // STRING_SPLIT_H
usingでstd::stringのコンストラクタと代入演算子を取り込んでいます。
特にstd::stringのコンストラクタは本当に多数あるのでそれを一々書くのはたいへんです。継承とusingのお陰でこんなに簡単に書けました。
使用例です。
#include <iostream>
#include "split.h"
int main()
{
StringSplit aString="abc,def,ghi";
aString += ",jkl";
while(StringSplit str=aString.split(','))
{
std::cout << str << " : " << aString << "\n";
}
}
std::stringクラス自身をそのまま残しておいて、外側で機能拡張することができます。つまり、他の派生クラスを設けて、また異なる機能拡張セットを導入できます。手続き型プログラミングにおけるサブルーチンのオブジェクト指向版的な感じですね。
注意事項:大事なことがあります。
STLを継承する時は、原則としてメンバ変数を定義しないことを強くお勧めします。もしくは、次回解説するようにprivate継承することをお勧めします。
「1-4.派生クラス変数へのポインタを基底クラスへのポインタへ変換できます」で説明したように、StringSplitへのポインタをstd::stringのポインタへ変換できます。つまり、std::string* p=new StringSplit;とすることができます。
そして、delete p;した場合、呼び出されるデストラクタはstd::stringのものです。StringSplitのデストラクタは呼ばれません。(コンパイラはpが指すオブジェクトがStringSplitであることを判別できないためです。)
従って、StringSplitにデストラクタを定義して、その中でリソースやメモリを開放していると、リソース/メモリ・リークします。更に、StringSplitはデストラクタを定義していないので問題ないように見えますが、問題が発生するケースがあります。
先程述べたようにコンパイラは自動的にStringSplitのデストラクタを生成します。そして、その中で各メンバ変数のデストラクタを呼び出します。そのメンバ変数のデストラクタでリソースやメモリを開発していると、同じくリークするのです。
例えば、メンバ変数としてstd::vectoraArray;を定義していたと仮定します。std:vectorのデストラクタはメモリの開放を行います。delete p;した時、StringSplitのデストラクタが呼出されないため、aArrayのデストラクタも呼出されず、メモリ・リークします。
さて今回、派生クラス変数へのポインタを基底クラスへのポインタへ変換して何が嬉しいのか、良く分からなかったと思いますが、この機能は、動的ポリモーフィズムを使う時に必要な機能なので、ここではそのようなことができることを理解しておいて下さい。
今回は「継承」の極基本的な部分を解説しました。
しかし、もう少し解説しておいた方が良い項目が残りました。次回も継続して「継承」について解説し、継承の秘密に迫ります。お楽しみに。
