
こんにちは。田原です。
難しい話が続いたので、ちょっと気楽にfor文について解説します。C++ではC言語にはなかった「イテレータ」が追加されました。そして、C++11ではコードがスッキリして可読性が上がる範囲ベースforを使えるようになりました。今回はこれらの使い方だけでなく仕組みについても解説します。
1.イテレータの使い方
各種のコンテナに保存されている要素を枚挙するために設計されたクラスがイテレータです。使い方はポインタによく似せられていますが、実体はクラスです。(各コンテナの内部で定義されています。)
1-1.ポインタによる記述
例えば、std::vectorの内容をポインタで枚挙する時は次のように書くことができます。(終了判定は違和感があるかも知れませんね。)
#include <iostream>
#include <vector>
int main()
{
std::vector<int> aVector={1, 2, 3, 4, 5};
std::cout << "Pointer\n";
for (int* p=&aVector[0]; p != &aVector[4+1]; ++p)
{
std::cout << *p << "\n";
}
}
1-2.イテレータによるforループ
同じことをイテレータを使うと次のように書くことができます。
#include <iostream>
#include <vector>
int main()
{
std::vector<int> aVector={1, 2, 3, 4, 5};
std::cout << "\niterator\n";
for (std::vector<int>::iterator it=aVector.begin(); it != aVector.end(); ++it)
{
std::cout << *it << "\n";
}
}
std::vector<int>::iteratorはstd::vector<int>用のイテレータです。
end()メンバ関数が「最後の要素」ではなく「最後の要素の次」を返すことで、上記のように!=判定で容易にループを回せます。もし、「最後の要素」を返されるとループをうまく回せません。そのため、(ちょっと分かりにくいですが)end()は「最後の要素の次」を返します。
1-3.autoを使って簡単化に
for文の中身がごちゃごちゃして読みにくいですが、C++11で導入されたautoを使うとスッキリします。
#include <iostream>
#include <vector>
int main()
{
std::vector<int> aVector={1, 2, 3, 4, 5};
std::cout << "iterator\n";
for (auto it=aVector.begin(); it != aVector.end(); ++it)
{
std::cout << *it << "\n";
}
}
この場合、aVector.begin()が返す値はstd::vector<int>::iteratorですので、コンパイラがautoをstd::vector<int>::iteratorと解釈してくれます。従って、itはstd::vector<int>::iterator型となります。ソースを書く人はauto一発で済むので大変楽になります。ただし、ソースを読む人はaVector.begin()の戻り値の型を調べないとitの型が分からないので意外に不便です。どちらを取るかはお好みです。
1-4.速度を気にする場合
end()関数を毎回呼び出してますが、これが何か重たい処理をしているかも知れせん。そのような場合にこのように記述すると無駄に遅くなる可能性があります。そこで、次のように記述する場合も多いです。
#include <iostream>
#include <vector>
int main()
{
std::vector<int> aVector={1, 2, 3, 4, 5};
std::cout << "iterator(auto)\n";
for (auto it=aVector.begin(), end=aVector.end(); it != end; ++it)
{
std::cout << *it << "\n";
}
}
なお、1-4のような書き方をして、かつ、ループの内部処理でend()が代わるような処理(要素の追加や削除)を行うと、確実におかしくなります。
1-3のように毎回end()と比較すれば大丈夫な場合も多いですが、はまりやすいです。最もよく使うコンテナはstd::vectorと思いますが、特にstd::vectorの場合、要素を追加する時に内部記憶領域を再獲得するため各要素のアドレスが変わることがあります。するとitが無効になるのです。結果、異常動作します。そもそもitが指している要素を削除すると当然itは無効になりますし、ループ内部で要素数が変化するような処理はなるべく書かない方が安全です。
1-5.イテレータのメリット
さて、イテレータはちょっと書き方が面倒ですね。そして、ここまでですと面倒なだけでメリットがないように見えます。
しかし、例えば、線形リスト(std::listなど)の場合、メモリ中に連続して要素が並びません。このような場合、ポインタで枚挙することはできません。ポインタをインクリメントするとポインタのアドレス値がポインタの指す型のバイト数だけ大きくなるだけですので、そこに「次の要素」が存在するとは限らないですから。(といいますか、普通はそこにありません)
#include <iostream>
#include <forward_list>
int main()
{
std::forward_list<int> aForward={1, 2, 3, 4, 5};
std::cout << "iterator(aForward)\n";
for (auto it=aForward.begin(); it != aForward.end(); ++it)
{
std::cout << *it << "\n";
}
}
上記のコードは最も簡単な線形リストであるstd::forward_listを用いた例です。枚挙処理はstd::vectorの時と同じ記述で済みます。本質的に同じ処理を同じ記述でかけるのは素晴らしいことです。
<algorithm>に様々な汎用アルゴリズムが用意されています。そして、これらはイテレータで処理対象を指定します。
つまり、イテレータを提供するコンテナについて、そのコンテナ内部の実装と無関係にこれらのアルゴリズムを適用できるのです。
イテレータは、データを枚挙して処理する多くのアルゴリズムが様々なデータ構造を処理できるようにする強力な仕組みなのです。
1-5.サンプル・コードのまとめ
2.イテレータの仕組み
さて、iteratorクラス、ちょっと不思議ですね。本物は様々な機能を持っているので複雑ですが、本質は実は簡単です。例えば、線形リスト・コンテナの場合を例にとって説明します。
2-1.線形リスト・コンテナ・クラスのサンプル
- Nodeクラス(内部のprivateクラスとして定義)
・ 次のNodeクラスへのポインタ
・ コンテナに保持する要素(サンプル・ソースではFooクラス) - 先頭Nodeへのポインタ
- デストラクタは先頭Nodeから追跡して全ての要素をdeleteする
- 先頭要素追加(push_front)関数
- 先頭要素削除(pop_frong)関数
- iteratorクラス(内部のpublicクラスとして定義)
・ Nodeへのポインタ
・ 前置インクリメント演算子(++)
・ 比較演算子(!=)
・ ポインタ解決演算子(->) - 先頭要素を指すイテレータを返却するbegin()関数
- 最終要素の次を指すイテレータを返却するend()関数
さて、以下の3つは見慣れないと思います。
・ ポインタ解決演算子(->)
・ 前置インクリメント演算子(++)
・ 比較演算子(!=)C++はクラスのメンバ関数として、これらの演算子を定義することができるのです。
そのメンバ関数の引数の数が決まっています。引数の型、戻り値の型、および、処理内容を自由に定義することができます。演算子のオーバーロードと呼ばれる機能です。なお、文法的には自由に機能を定めることができますが、元の意味とあまり大きく異ならないように定義することを強くお勧めします。例えば、`+`を`-`のように定義したら他のプロジェクトの仲間が酷い目に会いますから。
少し分解してサンプル・ソースを説明しつつ提示します。
2-1-1.コンテナへ記録するクラス
今回は次のような名前と年齢を記録するクラスFooを線形リスト型のコンテナへ記録します。
Fooクラスには内容を表示するためにメンバ関数print()を実装してみました。
class Foo
{
std::string mName;
unsigned mAge;
public:
Foo(std::string const& iName, unsigned iAge) : mName(iName), mAge(iAge)
{ }
void print()
{
std::cout << mName << "(" << mAge << ")\n";
}
};
2-1-2.簡単な線形リスト型のコンテナ
クラスFooを線形リストとして保管するクラスです。std::forward_listをFoo専用とし、更に重要部分だけ残して簡略化したイメージです。
次の部分はそのコンテナ・クラスのコンテナ機能を担う部分です。
class forward
{
// 1. Nodeクラス(内部のprivateクラスとして定義)
struct Node
{
Foo mFoo;
Node* mNext;
Node(Foo const& iFoo, Node* iNext) : mFoo(iFoo), mNext(iNext) { }
};
// 2. 先頭Nodeへのポインタ
Node* mHead;
public:
// コンストラクタ
forward() : mHead(nullptr) { }
// 3. デストラクタは先頭Nodeから追跡して全ての要素をdeleteする
~forward()
{
while(mHead) pop_front();
}
// 4. 先頭要素追加(push_front)関数
void push_front(Foo const& iFoo)
{
mHead = new Node(iFoo, mHead);
}
// 5. 先頭要素削除(pop_frong)関数
void pop_front()
{
Node* temp=mHead;
mHead=mHead->mNext;
delete temp;
}
(後略:この後にイテレータ機能を記述します。)
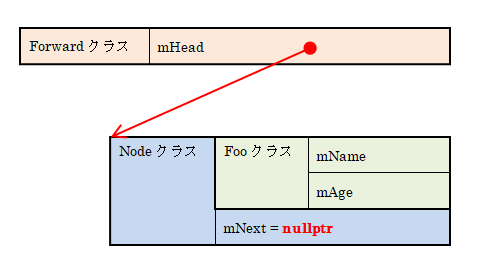
Fooと次のNodeへのポインタを持つNodeクラスによりFooクラスのデータを記録し、線形リストとして管理します。リスト先頭を指すmHeadポインタを使ってその線形リストの先頭要素をポイントしています。
例えば、Fooインスタンスを1つだけForwardクラスで管理している時のメモリは次のようになります。
push_front処理を図に示すと次のようなイメージになります。
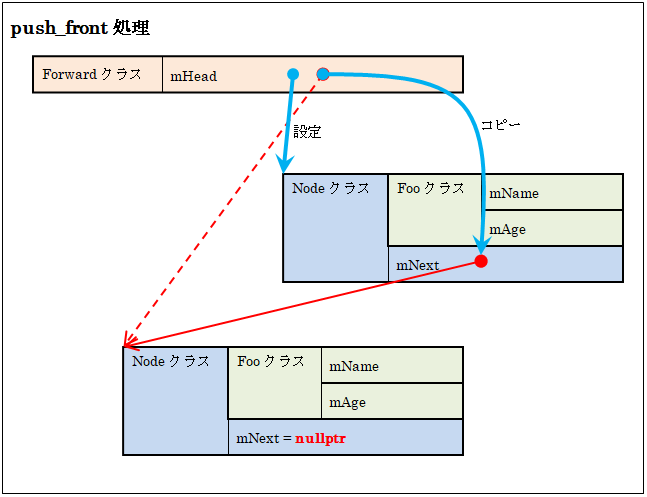
Nodeクラスをnewし、その時のmNextは直前のmHeadをコピーします。そして、mHeadで新規にnewされたNodeクラスのインスタンスをポイントします。pop_frontはその逆を行います。これで単純な線形リストを生成・管理できます。
2-1-3.簡単な線形リスト型のコンテナのイテレータ機能
STLにあるstd::forward_list等の各コンテナは、その全要素を操作するためのイテレータが定義されています。上記の簡易forward_listにも同様に簡単なイテレータを定義すると次のソースを使いします。
(上記のforwardクラス定義前半部分)
// 6. iteratorクラス(内部のpublicクラスとして定義)
class iterator
{
// Nodeへのポインタ
Node* mPointer;
public:
iterator(Node* iPointer) : mPointer(iPointer) { }
// 前置インクリメント演算子(++)
iterator& operator++()
{
mPointer=mPointer->mNext;
return *this;
}
// 比較演算子(!=)
bool operator!=(iterator const& iRhs)
{
return mPointer != iRhs.mPointer;
}
// ポインタ解決演算子(->)
Foo* operator->()
{
return &(mPointer->mFoo);
}
};
// 7. 先頭要素を指すイテレータを返却するbegin()関数
iterator begin()
{
return iterator(mHead);
}
// 8. 最終要素の次を指すイテレータを返却するend()関数
iterator end()
{
return iterator(nullptr);
}
};
イテレータ・クラスiteratorを定義し、先頭と最後の次のイテレータを返却するbegin(), end()メンバ関数を追加しています。
そして最後にメイン・ルーチンです。
int main()
{
forward aForward;
aForward.push_front(Foo("Taro", 30));
aForward.push_front(Foo("Hanako", 26));
aForward.push_front(Foo("Jiro", 23));
// イテレータによるforループ
std::cout << "--- iterator ---\n";
for (forward::iterator it = aForward.begin();
it != aForward.end();
++it)
{
it->print();
}
}
この処理により、Forwardクラスには次のようにデータが生成されます。
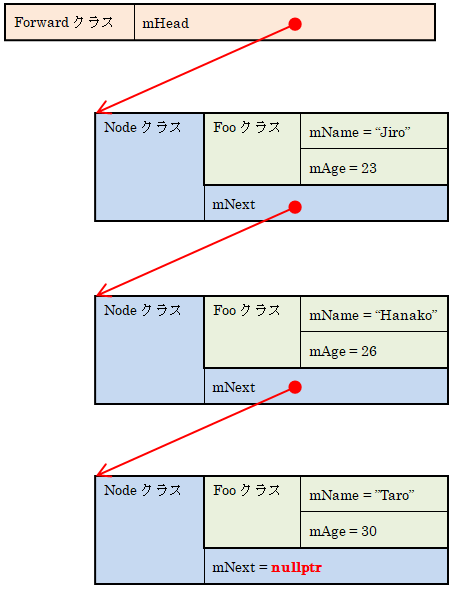
そして、「イテレータによるforループ」によるforループにより、内部で定義したiteratorクラスで全要素を枚挙しています。
begin()はmHeadが指す要素へのイテレータを返却します。
end()は最後の次です。最後はmName=”Taro”のNodeです。その次を指すmNextは常にnullptrですのでend()は常にnullptrを返却します。
そして、for文の;;中央でループ継続判断のために比較演算子(!=)を使います。
更に、for文の;;最後でループ変数更新処理のため、前置インクリメント演算子(++)を使っています。
std::forward_listと同じくForwardもmHeadから枚挙するのでpush_frontした順序と逆の順序ででてきます。
ちなみに、「1-4.イテレータのメリット」ではstd::forward_listから登録順で枚挙されているように見えますが、コンストラクタで逆順に登録されるためです。push_frontで登録すると逆順になります。
--- iterator --- Jiro(23) Hanako(26) Taro(30)
ところで、もし、ループ変数の更新時に後置インクリメント演算子や `+= 1`等の演算子を使いたい場合は、該当の演算子をiteratorクラスに定義しておく必要があります。
STLのイテレータはそれらの演算子の多くが事前に定義されていますので便利です。(ただし、オーバーヘッドがあるような演算子は定義されていないことがあります。)
2-2.STLのコンテナとイテレータについて
C++にはSTL(Standard Template Library)と呼ばれる標準ライブラリがあります。この中に多くのコンテナが定義されています。そして、それぞれのコンテナはイテレータが定義されています。
それらのイテレータはコンテナの特性に応じて5種類に分類されます。
| 名前 | 特徴 | 代表的な使い方 |
|---|---|---|
| Random Access Iterator | +=n等で離れた位置へ飛ぶことができ、Read/Write可能 |
配列やstd::vector |
| Bidirectional Iterator | インクリメントとデクリメントでき、Read/Write可能 | std::list |
| Forward Iterator | インクリメントのみ可能、かつ、Read/Write可能 | std::forward_list |
| OUtput Iterator | インクリメントのみ可能、かつ、Writeのみ | std::ostream |
| Input Iterator | インクリメントのみ可能、かつ、Readのみ | std::istream |
Input/Output Iteratorは、コンテナの要素を枚挙するためのイテレータではないので分かりにくいと思います。
std::istreamやstd::ostreamはデータの流れですが、これらは文字を枚挙することと本質的に同じです。
ならば、先に述べた標準ライブラリの<algorithm>に対して、直接std::istreamやstd::ostreamのデータを流し込んだり、取り出したりできるとスマートです。このようなストリームを直接algorithmで処理したいような時に、Input/Output Iteratorが便利です。
さて、これらのイテレータは継承関係にありますので、お互いに包含関係にあります。図にすると下記となります。なんとなくイメージを掴んで頂ければ幸いです。
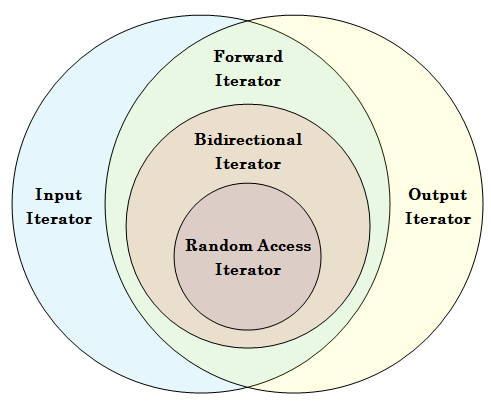
次の表はこれらのイテレータが定義されているSTLコンテナのリストです。
| コンテナ | 概要 | イテレータ |
|---|---|---|
| array | 固定長配列 | Random Access Iterator |
| vector | 可変長配列 | |
| deque | vectorより激しい変化に対応できる可変長配列 | |
| list | 双方向線形リスト(双方向連結リスト) | Bidirectional Iterator |
| set | キーの順序付き集合(キーの重複不可) | |
| multiset | キーの順序付き集合(キーの重複可) | |
| map | キーとデータの順序付き集合(キーの重複不可) | |
| multimap | キーとデータの順序付き集合(キーの重複可) | |
| forward_list | 片方向線形リスト(片方向連結リスト) | Forward Iterator |
| unorderd_set | キーの順序無し集合(キーの重複不可) | |
| unorderd_multiset | キーの順序無し集合(キーの重複可) | |
| unorderd_map | キーとデータの順序無し集合(キーの重複不可) | |
| unorderd_multimap | キーとデータの順序無し集合(キーの重複可) |
3.範囲ベースfor
3-1.範囲ベースforの使い方
前章までで説明したようにイテレータはなかなか強力なのですが、正直使い勝手は悪いと思います。
特に継続判定がうざいです。例えば、標準のalgorithmにはbeginとendを渡しますが、間違って別のコンテナのendを渡すと上述したように!=で継続判定するため無限ループになります。メモリ破壊しまくりですね。
algorithmをよくみるとイテレータは「開始」(begin)と「終了の次」(end)のペアで与えることも多いです。処理範囲を指定するのですから当然ですね。そこで、「開始」と「終了の次」のイテレータをペアにしたRange(範囲)が提案されています。n4560です。
また、「Iterators Must Go」(イテレータなんていらない)と言う主張もあります。
高橋 晃氏が「Iterators Must Go」を訳してみたで訳されてます。(先日まで【原文】と【日本語訳】はあったのですが今はなくなっしました。原文が削除されたからかも知れません。【Slideshare】は残ってます。)
主旨としては「iteratorは不便なのでRangeを使おう」って感じです。Rangeの具体的なメリットがたくさん列挙されています。
そのRangeを使うように拡張された for文が「範囲ベースfor」(range-based For)です。
お手軽にコンテナの中身を枚挙できるので便利です。
使い方は、概ね次のような形式が良いです。参照に「範囲」の「開始」から「終了」までの要素への参照が取り出されます。
for (auto& 参照 : 「範囲」)
{
// 参照を使った処理
}
もしくは、要素のサイズが小さく、かつ、内容を更新しない時は、下記が良いです。変数に「範囲」の「開始」から「終了」までの要素がコピーして渡されます。
for (auto 変数 : 「範囲」)
{
// 変数を使った処理
}
さて、まだ「範囲」(Range)は採用されていませんので、これだけでは役に立たないように見えます。しかし、実は「範囲」(Range)が満たすべき要件は、「開始」と「終了の次」のイテレータを取り出せることです。つまり、begin()とend()でイテレータを取り出せれば良いのです。
ということは、全てのSTLのコンテナが該当します。
更に、C++の生の配列も「コンテナ」として扱えるよう設計されています。
簡単な使用例です。
#include <iostream>
#include <forward_list>
class Foo
{
std::string mName;
unsigned mAge;
public:
Foo(std::string const& iName, unsigned iAge) : mName(iName), mAge(iAge)
{ }
void print()
{
std::cout << mName << "(" << mAge << ")\n";
}
};
int main()
{
int array[]={11,22,33,44,55};
std::cout << "--- raw-array ---\n";
for (auto i : array)
{
std::cout << i << "\n";
}
std::forward_list<Foo> aForwardList;
aForwardList.push_front(Foo("Taro", 30));
aForwardList.push_front(Foo("Hanako", 26));
aForwardList.push_front(Foo("Jiro", 23));
std::cout << "\n--- std::forward_list ---\n";
for (auto& element : aForwardList)
{
element.print();
}
}
3-2.範囲ベースforの仕組み
実はプリプロセッサがソースを展開してからコンパイラがコンバイルするように、コンパイラがソースをこっそり修正して修正したものをコンパイルします。
for (auto& 参照 : 範囲)
{
// 参照を使った処理
}
と書かれていて、かつ、「範囲」がbegin()とend()を持つ場合、次のようにこっそり修正してコンパイルされます。
なお、残念ながらitやendにアクセスすることはできません。
for (auto it=範囲.begin(), end=範囲.end(); it != end; ++it)
{
auto& 参照 = *it; // 範囲ベースfor用追加処理
// 参照を使った処理
}
「1-4.速度を気にする場合」にそっくりですね。「範囲ベースfor用追加処理」が追加されただけです。
また、「範囲」が生配列の場合は次のようにこっそり修正されます。(配列の要素数をNとします。&範囲[N]は最後の次の要素へのポインタです。)
for (auto it=&範囲[0], end=&範囲[N]; it != end; ++it)
{
auto& 参照 = *it; // 範囲ベースfor用追加処理
// 参照を使った処理
}
なお、厳密には異なります。判りやすさのため重要でない相違は省いてます。規格書のドラフトn3337の128ページ6.5.4 The range-based for statementに記載されています。範囲→range-init, it→__begin, end→__endです。
3-2-1.線形リスト・コンテナ・クラスのサンプルを範囲ベースforに対応
ということで、「2-1.線形リスト・コンテナ・クラスのサンプル」で記述した簡易版コンテナのイテレータに、operator*を追加するだけで範囲ベースforを使えるようになります。
#include <iostream>
#include <string>
//----------------------------------------------------------------------------
// コンテナに保管するクラス
//----------------------------------------------------------------------------
class Foo
{
std::string mName;
unsigned mAge;
public:
Foo(std::string const& iName, unsigned iAge) : mName(iName), mAge(iAge)
{ }
void print()
{
std::cout << mName << "(" << mAge << ")\n";
}
};
//----------------------------------------------------------------------------
// std::forward_listの簡略版
//----------------------------------------------------------------------------
class forward
{
// 1. Nodeクラス(内部のprivateクラスとして定義)
struct Node
{
Foo mFoo;
Node* mNext;
Node(Foo const& iFoo, Node* iNext) : mFoo(iFoo), mNext(iNext) { }
};
// 2. 先頭Nodeへのポインタ
Node* mHead;
public:
// コンストラクタ
forward() : mHead(nullptr) { }
// 3. デストラクタは先頭Nodeから追跡して全ての要素をdeleteする
~forward()
{
while(mHead) pop_front();
}
// 4. 先頭要素追加(push_front)関数
void push_front(Foo const& iFoo)
{
mHead = new Node(iFoo, mHead);
}
// 5. 先頭要素削除(pop_frong)関数
void pop_front()
{
Node* temp=mHead;
mHead=mHead->mNext;
delete temp;
}
// ---<<< 簡易イテレータ機能 >>>---
// 6. iteratorクラス(内部のpublicクラスとして定義)
class iterator
{
// Nodeへのポインタ
Node* mPointer;
public:
iterator(Node* iPointer) : mPointer(iPointer) { }
// 前置インクリメント演算子(++)
iterator& operator++()
{
mPointer=mPointer->mNext;
return *this;
}
// 比較演算子(!=)
bool operator!=(iterator const& iRhs)
{
return mPointer != iRhs.mPointer;
}
// ポインタ解決演算子(->)
Foo* operator->()
{
return &(mPointer->mFoo);
}
// 間接演算子(*)
Foo& operator*()
{
return mPointer->mFoo;
}
};
// 7. 先頭要素を指すイテレータを返却するbegin()関数
iterator begin()
{
return iterator(mHead);
}
// 8. 最終要素の次を指すイテレータを返却するend()関数
iterator end()
{
return iterator(nullptr);
}
};
//----------------------------------------------------------------------------
// メイン・ルーチン
//----------------------------------------------------------------------------
#include <forward_list>
int main()
{
forward aForward;
aForward.push_front(Foo("Taro", 30));
aForward.push_front(Foo("Hanako", 26));
aForward.push_front(Foo("Jiro", 23));
// イテレータによるforループ
std::cout << "--- iterator ---\n";
for (forward::iterator it = aForward.begin();
it != aForward.end();
++it)
{
it->print();
}
// 範囲ベースforによるforループ
std::cout << "\n--- range-based-for ---\n";
for (auto& foo : aForward)
{
foo.print();
}
return 0;
}
--- iterator --- Jiro(23) Hanako(26) Taro(30) --- range-based-for --- Jiro(23) Hanako(26) Taro(30)
4.まとめ
今回は主にイテレータの使い方とその仕組み、および、C++11で導入された範囲ベースforの使い方と仕組みを解説しました。
中身が分からないまま使うと苦労しますが、仕組みを把握すればスムーズに使えると思います。STLで定義されているものは結構複雑ですが、重要部分だけ抜き出すと意外に簡単です。今回はその簡単な部分を抽出してイテレータと範囲ベースforの考え方まで踏み込んで解説してみました。分かり易く書けていると良いのですが。
さて、今までサンプル・ソースでconstを説明しないまま使ってしまいました。本当はもっと早く解説したかったのですが、意外にconstの概念も難しいのです。しかし、そろそろconstを解説するために必要な概念の説明が終わったと思います。次回constについて解説します。お楽しみに。
