
こんにちは。田原です。
前回までで構造体とポインタについて解説しました。今回は更に配列を解説します。
そして、これらの3つを組み合わせは複雑です。特に構造体の配列へのポインタと構造体へのポインタの配列はややこしいです。しかし、メモリにどのように配置されるのか把握することで、理解しやすくなります。そこで、これらのメモリ状の配置について図解を交えて解説します。
C++は様々な配列をサポートしていますが、コア言語が提供するものは固定長配列です。
C言語との互換性を維持しているため例外的な振る舞いが多く、あまり使い勝手は良くないですが、軽いです。
同じ型の変数を多数「一列」に並べたものが1次元配列です。直線的に並んでいるので1次元です。
下記の構文で定義します。
型名 配列名[要素数]; // ①
型名 配列名[要素数]={初期化リスト}; // ②
型名 配列名[]={初期化リスト}; // ③
①②は「型名」の型の要素を「要素数」だけ一列に並べた「配列名」の配列を定義します。
③は「型名」の型の要素を「初期化リスト」の数だけ一列に並べた「配列名」の配列を定義します。
①は初期化方法を指定していませんので、基本型は原則として初期化されないため要注意です。
②③の「初期化リスト」は要素の値をカンマで区切って複数個並べます。
型が構造体やクラス等でコンストラクタを持つ場合、要素の値はそのコンストラクタの実引数となります。もし、引数が複数個ある場合は、{}で括って指定します。
②の場合で、初期化リストの数が要素数より小さい時、初期化リストが不足した要素については
- 基本型ならば「ゼロ初期化」と呼ばれる初期化方法で0で初期化されます。
- クラス(classやstruct)の場合はデフォルト・コンストラクタで初期化されます。
配列名[要素番号]
でアクセスします。要素番号は必ず0から始まり、要素数-1までです。
例えば、要素数4の場合、要素番号は0, 1, 2, 3を指定できます。
Foo foo[4]={1, {2}, {3, 4}};
にて、Foo構造体型の変数を4つ持つ配列fooを定義しています。
この時、2つの要素の値を指定した初期化リストで初期化しています。
- 先頭の要素の値は1なので、仮引数が1つのコンストラクタが呼ばれます。
- 次の要素の値は{2}です。この場合も仮引数が1つのコンストラクタが呼ばれます。
- 更に次の要素の値は{3, 4}です。2つの実引数を指定しているので仮引数が2つのコンストラクタが呼ばれます。
- 初期化リストが1つ不足してますので、最後の要素はデフォルト・コントスラクタで初期化されます。
#include <iostream>
struct Foo
{
int mData0;
int mData1;
Foo() : mData0(0), mData1(0)
{
std::cout << "Foo::Default Constructorn";
}
Foo(int iData0) : mData0(iData0), mData1(10)
{
std::cout << "Foo::Constructor(" << iData0 << ")\n";
}
Foo(int iData0, int iData1) : mData0(iData0), mData1(iData1)
{
std::cout << "Foo::Constructor(" << iData0 << ", " << iData1 << ")\n";
}
};
int main()
{
Foo foo[4]={1, {2}, {3, 4}};
for (int i=0; i < 4; ++i)
{
std::cout << "[" << i << "] " << foo[i].mData0 << ", " << foo[i].mData1 << "\n";
}
return 0;
}
そして、char型配列の場合は次のような初期化構文も使えます。
char 配列名[]=文字列定数;
文字列定数もNULL終端ですので、もし5文字の文字列の場合、最後にNULL文字が追加されるため、要素数6の配列になります。
例えば、次のように書きます。
char str[]="12345";
C言語では文字列をchar型変数の配列として定義し、かつ、文字列の終わりは値0の文字(NULL文字)とすると定義しました。文字列を「文字列型」のような型を追加するのではなく「配列」を使用することでコアの言語仕様を単純に保ちつつ文字列を取り扱えるようにしたと言う点で画期的な方法でした。
この仕様を適切に使えるようにするため、配列名は配列型ではなく配列先頭へのポインタと決められました。
これにより文字列はchar*(文字型へのポインタ)でハンドリングでき、配列名をそこへ代入することができるのです。
さて、ここまでは良いのですが、ここからが問題です。まず、次のサンプル・ソースを走らせて見て下さい。(警告が表示されますが、取り敢えず気にしないで下さい。後ほど説明します。)
#include <iostream>
void Foo(char* iStr)
{
std::cout << "Foo : " << iStr << " size=" << sizeof(iStr) << "\n";
}
void Bar(char iStr[6])
{
std::cout << "Bar : " << iStr << " size=" << sizeof(iStr) << "\n";
}
int main()
{
char str[]="12345";
std::cout << "main : " << str << " size=" << sizeof(str) << "\n";
Foo(str);
Bar(str);
return 0;
}
配列は要素数情報も含みます。上記のstrは文字型6個の配列ですから要素数をコンパイラが把握できますので、sizeof()演算子で配列の全バイト数である6が返却されます。
しかし、Foo()関数のiStr仮引数はchar*型です。strがiStrへ代入された時点でstrが持っていた要素数は失われ単なるポインタに「成り下がって」しまいますので、sizeof(iStr)はchar*型(=ポインタ型)のバイト数を返却します。上記サンプルをWandboxで走らせた場合、Wandboxは64ビット・ビルドですので、sizeof(iStr)は8バイト(=64ビット)を返却します。
そこで、配列を配列のまま渡したくてBar()関数のように定義してみました。
しかし、残念ながらBar()関数のように定義してもiStrはchar*として解釈されます。「要素数6」という情報は失われてしまい、iStrはポインタ型となり、sizeof(iStr)はポインタ型のサイズを返却します。
この仕様の主旨は良く分からないのですが、配列名は「配列型」ではなく「配列先頭へのポインタ」として統一的に取り扱うための仕様ではないかと思います。(*1)
そして、Bar()関数のような使い方をすると意図した通りに動作しないからと思いますが、Wandboxの例のようにgccでは警告がでます。Visual C++は残念ながら警告してくれないようです。
そして、以上の仕様は文字配列だけではなく全ての型の配列に適用されます。int型やクラスの配列の場合でも配列名は、その配列先頭へのポインタとなります。
このように「配列名」の型は「配列」ではなく要素数情報が抜け落ちたポインタ型になってしまうことがC++のコア部分が提供する配列の要注意点です。
(*1)配列名がポインタ型でない例
配列名がポインタ型でない代表的な例はsizeof()演算子です。
このお陰で`sizeof(配列名)/sizeof(配列名[0])`で配列の要素数を取り出すことができます。他にも「配列型へのポインタ」や「配列型の参照」と言う使い方もありますが、こちらは入門時代に使うことはありませんし、ポインタと配列の混乱を助長しますので、入門講座では取り扱いません。
C++の配列は多次元配列も使えます。考え方は単純で、「1次元配列」が更に1列に並ぶと「2次元配列」になり、更に「2次元配列」が1列に並んだものが「3次元配列」になります。以下同文です。
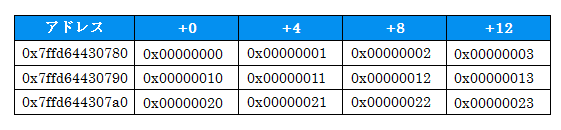
int bar[3][4]=
{
{0x00, 0x01, 0x02, 0x03},
{0x10, 0x11, 0x12, 0x13},
{0x20, 0x21, 0x22, 0x23}
};
は、int型が3行4列並んだ配列です。
初期化リストを見ると分かりやすいですが、4つの塊が3つ存在しています。
つまり、「4つの要素を持つ1次元配列」が3つ並んだものになっています。
Wandboxで試してみる
そして、アドレスを良く見て下さい。この例ではint型が4バイトですので列方向にアドレスが4バイトづつ増えています。
3次元配列にすると、更にこの平面が立体的に重なるイメージになります。
構造体、配列、ポインタ、それぞれ単独ではそれほど複雑ではありません。
構造体とポインタくらいまでは、なんとかなる人も多いのではないでしょうか?
しかし、先にも述べたように、配列名がポインタになりますから、配列とポインタは混乱しがちです。
そして、ややこしいのは「造体の配列へのポインタ」と「構造体へのポインタの配列」です。
そこで、この2つについて補足します。
#include <iostream>
#include "dump.h"
struct Foo
{
int mInt;
unsigned mUnsigned;
Foo(int iInt, unsigned iUnsigned) :
mInt(iInt),
mUnsigned(iUnsigned)
{ }
};
int main()
{
// Foo and pointer
Foo foo(0x11223344, 0x55667788);
Foo* foo_ptr=&foo;
dump(std::cout, "foo_ptr", foo_ptr);
dump(std::cout, "foo", foo);
dump(std::cout, "*foo_ptr", *foo_ptr);
// array of Foo
Foo foo_array[]={{0x10, 0x20}, {0x30, 0x40}, {0x50, 0x60}};
Foo* foo_array_ptr=foo_array;
dump(std::cout, "foo_array_ptr", foo_array_ptr);
dump(std::cout, "foo_array", foo_array);
dump(std::cout, "*foo_array_ptr", *foo_array_ptr);
// 3 of Foo and array of pointer
Foo foo0(0x80, 0x90);
Foo foo1(0xA0, 0xB0);
Foo foo2(0xC0, 0xD0);
Foo* foo_ptr_array[]={&foo0, &foo1, &foo2};
dump(std::cout, "foo_ptr_array", foo_ptr_array);
dump(std::cout, "foo0", foo0);
dump(std::cout, "foo1", foo1);
dump(std::cout, "foo2", foo2);
return 0;
}
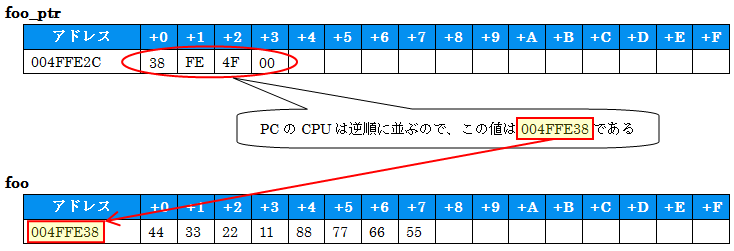
foo_ptr +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE2C : 38 fe 4f 00
foo +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE38 : 44 33 22 11 88 77 66 55
*foo_ptr +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE38 : 44 33 22 11 88 77 66 55
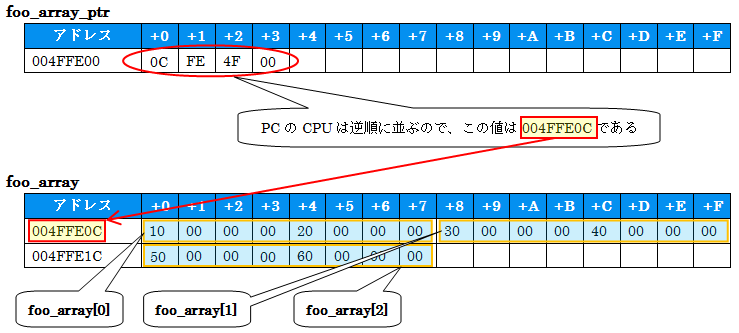
foo_array_ptr +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE00 : 0c fe 4f 00
foo_array +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE0C : 10 00 00 00 20 00 00 00 30 00 00 00 40 00 00 00
004FFE1C : 50 00 00 00 60 00 00 00
*foo_array_ptr +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFE0C : 10 00 00 00 20 00 00 00
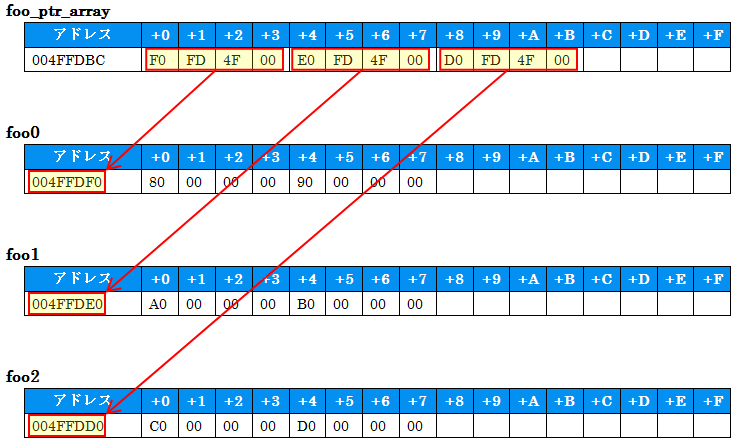
foo_ptr_array +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFDBC : f0 fd 4f 00 e0 fd 4f 00 d0 fd 4f 00
foo0 +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFDF0 : 80 00 00 00 90 00 00 00
foo1 +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFDE0 : a0 00 00 00 b0 00 00 00
foo2 +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +a +b +c +d +e +f
004FFDD0 : c0 00 00 00 d0 00 00 00
Foo and pointer にて、構造体Fooの変数を1つ確保し、そこへのポインタfoo_ptrを設定しています。それぞれの内容をダンプしました。次の図のようなメモリ配置になっています。
array of Foo にて、構造体Fooを要素として3つ持つ配列を確保し、その先頭へのポインタfoo_array_ptrを設定しています。それぞれの内容をダンプしました。次の図のようなメモリ配置になっています。
3 of Foo and array of pointer にて、構造体Fooの変数を3つ定義し、「それぞれへのポインタ」3つを要素とする配列を確保しています。それぞれの内容をダンプしました。次の図のようなメモリ配置になっています。
今回は配列の定義方法を中心に解説しました。
C++の配列は特に構造体やポインタと組み合わせた時に混乱しやすいですので、その組み合わせを中心に図解しました。サンプル・ソースと実行結果、および、図を照らし合わせてることで理解が進みます。
またこれは、メモリの状態を頭の中で思い浮かべる練習にもなると思います。C++で高速なプログラムを開発する際に1つの重要なスキルになりますので、たいへんですが是非頑張って見て下さい。
さて、今回はC++のコア言語が提供する配列について解説しましたが、次回は標準ライブラリ(STL)が提供する配列(std::vector)について解説します。また、C++のキモの1つである参照についても次回解説したいと思います。C言語のキモはポインタでした。C++のキモはたくさんありますが、その中の一つは参照と思います。
ポインタに似ていますがポインタとは結構異なります。より安全なプログラムを開発する際に有用です。
お楽しみに。
