
こんにちは。田原です。
既に軽くポインタを使ってきましたが、ここできちんと解説したいと思います。
ポインタは理解することが難しいと良く言われます。確かにある種のハードルがあります。そのハードルは今まで解説してきたメモリとアドレスの概念を理解することと思います。それさえ分かれば理解することは簡単です。
しかし、ポインタは高速ですが、その分 危険性がかなりあります。今回はどんな危険があるのかについても解説します。
第4回目 コンピュータの仕組みについてで軽く説明したように、ポインタは変数です。ポイントしている先の変数が記録されているメモリのアドレスが入っています。
int aData=100; int* aPointer=&aData;
第4回で説明したように、上記のようにプログラムすると、例えばVisual Studio 2015で32ビット・ビルドすると下記のようなメモリ配置になります。(アドレスの具体的な値は変化します。)

ポインタは型名に*(アスタリスク)を付けたものですので、ポインタ変数は下記のようにして定義します。
型名* 変数名;
例えば、以下のaIntはint型変数へのポインタ、aFooはFoo型変数へのポインタです。
struct Foo { unsigned mData; };
int* aInt;
Foo* aFoo;
ところで、ポインタの定義方法の流儀はもう一つあります。
int *aInt;
です。微妙な差ですが、*がint側ではなくaInt側に付いてます。文法的にはどちらもOKです。
変数を複数同時に定義することを考えると、この方が間違いが少ないと言う流儀です。
例えば、下記のように書くと、aInt0はポインタですが、aInt1はポインタではないint型です。
int* aInt0, aInt1;
これを防ぐためには変数名側に*を付けた方が良いですね。
int *aInt0, *aInt1;
これはC言語時代からの流儀です。C言語は比較的型が単純な言語ですのでこれで十分と思います。
しかし、C++は型が非常に複雑です。その複雑化する主要因に*以外に&とconstがあります。それらが何を修飾するのか判断するのが結構難しいのです。
int*& aInt0;
は、aInt0は「int型変数へのポインタ」の参照という意味です。
int *&aInt0;
と書くと、上記と同じ意味なのですが、日本語で表現しづらく、結果として理解し難くなります。
ですので、できるだけ型の記述を分かりやすくした方が習得が早くなると思います。
そこで、1行で1宣言が私からのお勧めです。初期化を一緒に書いても見難くなりませんし。
int* aInt0=nullptr; int* aInt1=nullptr;
第6回目で軽く触れましたが、ポインタに直接関連する演算子が幾つかあります。そのなかでよく使われるものが4つあります。
| 演算子名 | 演算子 |
|---|---|
| アドレス | & |
| 間接演算子 | * |
| 加減算 | +, -, ++, -- |
| 間接メンバ・アクセス演算子 | -> |
アドレスは、「変数」に前置することでその変数へのポインタになります。
間接演算子は、ポインタに前置することでポインタの指す変数そのものを意味します。
int型変数を定義して100を設定します
int aData=100;
int型へのポインタを定義し、&演算子でaDataへのポインタを取り出して設定します。
int* aPointer=&aData;
*演算子でaPinterの指す変数aDataへ(ポインタを経由して間接的に)アクセスできます。
std::cout << "*aPointer=" << *aPointer << "\n";
先程、ポインタを定義する時は、int *aInt0;ではなくint* aInt0;と書くことをお勧めしましたが、この間接演算子とポインタ定義の混乱を防ぐのにも有効です。
int *aPointer=&aData; *aPointer=200;のそれぞれの行は意味が全く異なりますが、同じ表記になるため、混乱しがちです。
前者は宣言と同時に初期化しているので、aPointerに変数aDataのアドレスを設定しています。
後者は宣言文ではない実行文ですので、aPointerが指変数aDataに200を設定しています。
Wandboxで色々試してみる
また、整数の加算・減算も定義されています。ポインタに1加えると、アドレスが1増えるのではなく、ポイントしている型のバイト数分増えます。
例えば、int型が4バイトの処理系で、int型へのポインタpにアドレス0x1000が入っていたとします。この時、(p+1)は0x1004です。(p+2)は0x1008となります。
インクリメント/デクリメント演算子の時も同様です。
上記のpに対して、++pするとpの値は0x1004へ変化します。続けて、p++するとpの値は0x1008へ変化します。
ポイント先が構造体やクラスの場合、それぞれのメンバ変数へアクセスするための演算子->があります。
「ポインタ名->メンバ変数名」の構文でアクセスできます。
struct Foo
{
unsigned mData0;
int mData1;
Foo(unsigned iData0, int iData1) : mData0(iData0), mData1(iData1) { }
};
Foo foo(123, 456);
Foo* aFoo=&foo;
std::cout << aFoo->mData0 << std::endl;
std::cout << aFoo->mData1 << std::endl;
2017年4月7日「1-2-4.間接メンバ・アクセス演算子」の解説を追加しました。
NULLポインタと呼ばれるある「何もポイントしていない」ことを示すポインタの値があります。
NULLポインタに対しては様々な要求があり、それらを満たすためC++11で専用の型と値が定義されました。
| 型 | 値 |
|---|---|
| std::nullptr_t | nullptr |
std::nullptr_tと言う型は特殊です。通常、任意の「型」として定義された変数は取りうる値が複数あります。しかし、std::nullptr_tは取りうる値はnullptr1つだけです。
そして、nullptrは値ですので右辺値です。
C/C++のポインタはメモリがないところを指すことができますし、間違って意図した変数と異なる変数を指すこともできます。
そのような場所を指している時に、指している先をアクセスするとプログラムが異常終了することが多いです。異常終了すればまだ良い方で、異常終了せず意図しない動作を続ける場合もあります。
他の言語について
これがC/C++の最も危険な部分です。この問題を避けるようなD言語やRustなど様々な言語が提案されています。
適切にこの問題を回避できC/C++を置き換える言語が出現すると人類にとってたいへん望ましいと思います。
しかし、今のところC/C++を置き換えることに成功した言語はありません。過去の歴史が物語っているのですか、根本的な部分を見直すと膨大なソフトウェア資産の継承が難しくなるため、置き換えられるにはかなり長い年月を必要とすると思われます。
不正アクセスの典型例は、NULLポインタ・アクセスです。「ぬるぽ」と表現されることがありますが、それのことです。
簡単に示すと下記の2行目がNULLポインタ・アクセスです。
int* aPointer=nullptr; std::cout << *aPointer << "\n";
こんなに分かりやすいケースだけであれば問題になることは無いのですが、aPointerにnullptrを設定しているところが遥か遠くにあると、意外に見落としてしまうのです。そして、プログラムが異常終了します。
ポインタを使った時の一番怖いバグです。意図していなかった領域をいつの間にかポイントしてしまい、そこに書き込んでしまうことです。
早速、サンプルです。
#include <iostream>
struct Data
{
int data0;
int data1;
short data2;
short data3;
Data() : data0(0), data1(0), data2(0), data3(0) { }
};
int main()
{
Data data;
data.data0=1000;
data.data1=2000;
data.data2=3000;
data.data3=4000;
std::cout << "----- address -----\n";
std::cout << "&data.data0=" << &data.data0 << std::endl;
std::cout << "&data.data1=" << &data.data1 << std::endl;
std::cout << "&data.data2=" << &data.data2 << std::endl;
std::cout << "&data.data3=" << &data.data3 << std::endl;
std::cout << "----- data -----\n";
std::cout << "data.data0=" << data.data0 << std::endl;
std::cout << "data.data1=" << data.data1 << std::endl;
std::cout << "data.data2=" << data.data2 << std::endl;
std::cout << "data.data3=" << data.data3 << std::endl;
std::cout << "----- modify -----\n";
// modify data0
int* p=&data.data0;
std::cout << "*p =" << *p << std::endl;
*p=5000;
std::cout << "data.data0=" << data.data0 << std::endl;
// modify data11
std::cout << "*(p+1) =" << *(p+1) << std::endl;
*(p+1)=6000;
std::cout << "data.data1=" << data.data1 << std::endl;
// error!!
std::cout << "*(p+2) =" << *(p+2) << std::endl;
*(p+2)=7000;
std::cout << "data.data2=" << data.data2 << std::endl;
std::cout << "data.data3=" << data.data3 << std::endl;
return 0;
}
project(pointer-error1)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
endif()
add_executable(pointer-error1 pointer-error1.cpp)
----- address ----- &data.data0=00CFFC5C &data.data1=00CFFC60 &data.data2=00CFFC64 &data.data3=00CFFC66 ----- data ----- data.data0=1000 data.data1=2000 data.data2=3000 data.data3=4000 ----- modify ----- *p =1000 data.data0=5000 *(p+1) =2000 data.data1=6000 *(p+2) =262147000 data.data2=7000 data.data3=0
上記プログラムの構造体Dataであるdata変数は次のようなメモリ配置になります。
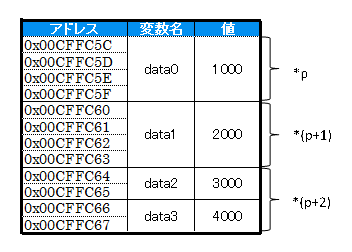
pはint型へのポインタですので、short型変数data2を指している時でもint型サイズの領域をポイントします。
従って、最後の*(p+2)はdata2とdata3の領域を纏めてint型変数として処理してしまいます。
そのため、*(p+2)を出力した値は不可解な値ですし、設定するとdata3が0クリアされてしまいます。(これは7000の上位2バイトが0だからです。)
比較的やらかしやすいミスにローカル変数へのポインタを返却するミスがあります。
通常のローカル変数(staticでないローカル変数)は関数からreturnすると解放されますので、通常のローカル変数へのポインタを返却した場合、それは不正な領域へのポインタとなります。
Visual C++では警告がでます。gccでは警告が出る上にNULLポインタを返却してくれますので、実行時に異常終了することが期待できます。そのため、バグに気が付きやすいですが、全てのコンパイラが親切に警告してくれるとは限りませんので要注意です。
下記サンプルは、関数Fooでfoo.dataに1000を設定し、そこへのポインタを返却しています。
foo.dataはその後、修正していないので1000のままのはずですが、関数Barを呼ぶことで書き換わってしまいます。(*1)
foo.dataがスタック上に記録されていますが、関数Fooがローカル変数を記録するのに用いるスタック領域は関数Fooから戻る時に解放されます。そして、関数Barが呼ばれた時にその解放されたスタック領域が使用されるため、foo.dataと同じ領域に関数barのローカル変数が割り当てられてしまうことが原因です。(第9回目の解説も合わせてご覧下さい。)
Visual Studioでは警告は出ますが異常終了しないため、foo.dataが化けたかのように見えます。
通常通り動作しつつ、内部的には異常な値に化けているのでたいへん危険なのです。
コンパイラ警告には良く注意を払うようにして下さいね。
(*1)
struct Dataのdummy_data[]で細工してこのように調整しています。std::coutが使うスタック領域を避けてfoo.dataを割り当てるようにしているのです。通常はstd::coutで出力する際に化けます。
#include <iostream>
struct Data
{
int data;
int dummy_data[1000];
Data(int init) : data(init), dummy_data() { }
};
int* Foo()
{
Data foo=1000;
std::cout << "&foo.data=" << &foo.data << std::endl;
return &foo.data;
}
int* Bar()
{
Data bar=2000;
std::cout << "&bar.data=" << &bar.data << std::endl;
return &bar.data;
}
int main()
{
int* foo_data=Foo();
Bar();
std::cout << "foo_data =" << foo_data << std::endl;
std::cout << "*foo_data=" << *foo_data << std::endl;
return 0;
}
project(pointer-error2)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
endif()
add_executable(pointer-error2 pointer-error2.cpp)
(以下、CMakeLists.txtはプロジェクト名、excutable名、ソースファイル名が異なるだけですので省略します。)
比較的レアケースと思いますが、ローカル変数へのポインタを例えばグローバル変数で保持すると、エラーや警告も出ず、異常終了さえしない、たいへん分かりにくいミスも存在します。
こちらはVisual Studioとgccのどちらとも異常終了しませんし、警告もでません。
やらかしてしまうと、発見がたいへん難しいバグになります。
しかし、ローカル変数へのポインタをどこかに記録しない限り発生しない不具合ですので、出来る限りローカル変数へのポインタをローカル変数以外のポインタ変数へ記録しないことがお勧めです。
どうしても必要な時は、ポイント先のローカル変数を解放した後もその記録が残っていないか、机上チェックを丁寧に行うことをお勧めします。
#include <iostream>
int* gPointer;
void foo()
{
int foo_data=1000;
std::cout << "&foo_data=" << &foo_data << "\n";
gPointer=&foo_data;
}
void bar()
{
int bar_data=2000;
std::cout << "&bar_data=" << &bar_data << "\n";
}
int main()
{
foo();
bar();
std::cout << "*gPointer=" << *gPointer << "\n";
return 0;
}
恐らく、ぬるぽの次にお目にかかることが多いポインタ・バクではないかと思います。
std::vectorという、動的に要素数を変更できる配列が標準ライブラリ(STL)で提供されます。
これはランダムアクセス性能を確保するため、連続した領域を配列に割り当てて使います。
そして、連続領域が取れない場合、別の領域へ割り当て直します。
そのため、ある要素へのポインタを獲得した後、要素数を増やすなどした場合、そのポインタの指す領域が不正になる場合があるのです。
下記はその再現サンプルです。count3ポインタにarray[3]のアドレスを設定していますが、その後、push_back()して要素数を増やした結果、メモリの再割当てが発生し、array[3]のアドレスが変わってしまいましたので、*countを変更してもarray[3]へ反映されません。
このサンプルの影響ならばまだ良いのですが、count3が指している領域は解放されたため、他の領域に再割当てされる可能性があります。その時、2-2で述べたような不正ポインタとなり、想定外の領域を破壊するので非常に痛いバグになります。
std::vectorを使う時は、原則として要素へのポインタを保持しないことをお勧めします。
要素へのポインタを保持する必要が有る時は、要素数を増やした後でそのポインタ経由でアクセスしていないか、良くチェックされて下さい。
#include <iostream>
#include <vector>
int main()
{
std::vector<int> array;
int* count3=nullptr;
for (std::size_t i=0; i < 5; ++i)
{
int input;
std::cout << "[" << i << "] number? ";
std::cin >> input;
array.push_back(input);
if (i == 3)
{
count3=&array[i];
}
std::cout << "array[" << i << "]=" << array[i] << "\n" << std::endl;
}
std::cout << "--------\n";
*count3=*count3*10;
std::cout << "*count3 =" << *count3 << std::endl;
std::cout << "array[3]=" << array[3] << std::endl;
std::cout << "count3 =" << count3 << std::endl;
std::cout << "&array[3]=" << &array[3] << std::endl;
return 0;
}
ポインタの注意事項について解説しました。なかなか頭の痛いバグを作り込み易いことに驚かれたかも知れません。
これは高速に動作するプログラムを開発するための代償ではないかと思います。もしかすると将来このような問題のない小規模なシステムでも高速に動作するプログラムを開発できる処理系が開発されるかも知れません。しかし、現在はまだC++を置き換えることができた言語は現れていません。
仕組みを知っていればこれらの問題を避けることができますので、より高速なプログラムを開発できるようになります。是非ポインタを使いこなして下さい。
今回、配列と構造体とポインタの複合まで解説する予定だったのですが、ポインタの使用上の注意点を丁寧に解説した方が良いことに気がついたので、そこまで届きませんでした。
次回こそは配列と構造体とボインタが織りなす三角関係について解説したいと思います。おたのしみに。
