
こんにちは。田原です。
今回は、前回に引き続き、文字の内部表現について解説します。まず¥マーク問題、次に日本語文字コードについて解説します。文字コードについては本当に奥深いのですが、ここでは各種表示を日本語で出力する程度の「普通」の日本語対応するプログラムを開発する際に知っておくべきこと中心に解説します。
特に昔から日本語対応が進んでいたWindowsは過去幾つかの不幸な決定が重なった結果、頭の痛い問題が複数あります。そして、互換性の維持のためなかなか対策できず、未だに完全解決には程遠い状態です。それらの問題が発生する仕組みと問題を軽減する対策についても一部解説します。
既に経験された方も多いと思いますが、¥マークが \(バックスラッシュ)に化けるように見える問題です。原因は簡単です。¥マークと\(バックスラッシュ)は文字コードが同じ値なのです。どちらとも0x5cなのです。次のようになっているわけです。

では、文字コードが同じなのに、どうやって¥マークと \(バックスラッシュ)を切り替えているのでしょう?
前回説明したように文字の形状を定めているのはフォントでしたね? つまり、その文字を表示する時に使ったフォントによって変わるわけです。
ということは、0x5cの¥マークと\(バックスラッシュ)は、C++は完全に同じものとして取り扱います。それを画面に表示した時に形が異なりますが、それは人にしか見えません。C++には見えないのです。
さて、何故このようなことになったのでしょう?
その昔1970年前後にISO 646という国際標準が制定されました。これは7ビットで表現できるコンピュータの文字コードを定める規格です。その時、幾つかの文字コードは国毎に自由に定めて良いことに決まりました。その1つが0x5cです。
そして、アメリカは\(バックスラッシュ)、日本はJISで¥マークと定めたわけです。
この文字が単に表示だけに用いられるものでしたら、文字が変わることだけ知っていれば大した問題にならないのですが、この文字はコンピュータにとって特別な意味が割り当てられています。
- C言語等のエスケープ文字
‘\n’は改行コードを示します。nの前に¥マークを置いて「エスケープ」することで改行文字を表現しました。他にも多数のエスケープ・シーケンスがあります。 -
Windowsのフォルダの区切り記号
“C:¥Windows¥System32″などフォルダを区切る時、¥マークが使われます。
後述しますが、エスケープ文字と同じ文字を区切り記号にするというマイクロソフトの決定は世界中の多くのプログラマを苦労させていると思います。
昔はルート・フォルダしかありませんでした。MS-DOS 2.0で「階層化ディレクトリ」と呼ばれていたUnixの機能をMS-DOSへ取り込んだ時に区切り記号が \(バックスラッシュ)でした。Unixは当時も現在と同じく /(スラッシュ)で区切っていましたので、同じスラッシュを使ってくれてればと恨めしいです。
Windowsではほとんどの場合¥マーク、Linuxではほとんどの場合\(バックスラッシュ)、Macでは¥マークだったり、\(バックスラッシュ)だったりします。
Windowsしか使わなければ問題ないですが、WEB技術はUnix/Linux由来のものが多く、\(バックスラッシュ)で表示されることもあります。その結果「何故、\になるのですか?」と言うFAQが発せられます。
当ブログのようにソースを提示する時、頭痛いです。普通に記述するとWindowsでも \(バックスラッシュ)になります。”¥”と書けば¥マークになるのですが、ソースをコピペした時、コンパイルできません。結局、フォント指定を工夫して対処してます。(MSゴシックを先頭、次に0x5cが \(バックスラッシュ)で表示されるフォントを指定。MSゴシックがあれば¥マーク、無いなら \(バックスラッシュ)で表示されます。)
¥マークはフォルダの区切り記号でもあり、エスケープ文字でも有ります。なので、¥マーク1文字だけでは区切り記号の意味になりません。もし、”C:¥notes”のようなフォルダを、C++で”C:¥notes”と書くと、”C:[改行]otes”と解釈されます。正しくは”C:¥¥notes”と書く必要があります。
しかし、いつ頃からなのか把握していませんが、少なくとも最近のWindowsはLinuxと同じく、/(スラッシュ)をフォルダの区切り記号として受け入れます。ですので”C:/notes”のように書いても正しくアクセスできるようです。#include <boost/format>など#includeを書く時は /(スラッシュ)を使うとマルチ・プラットフォーム対応できますので、お勧めします。
細かい話は後述しますが、WindowsはShift-JISと言う文字コードで日本語を扱う機能を持ってます。std::stringやchar*で文字列を取り扱う際に日本語を使いたい場合のWindows標準です。
Shift-JISは漢字1文字を2バイトで表現します。そして、その2バイト目に 0x5cが使われている文字が多数あります。例えば、ソ、構、能、表などなどです。
このような文字を使ったフォルダ名を含むパス文字列を、Shift-JISを理解しないプログラムやライブラリに与えると、その途中にある0x5cを\(バックスラッシュ)と解釈し、区切り記号として処理します。その結果、指定したフォルダやファイルがあるのに”Not found”エラーになる場合があります。
この問題は日本語を含むフォルダを使わないくらいしか対策がありません。ですので、海外製のプログラムやライブラリを使う場合は、なるべくフォルダに日本語を使わない方がトラブルが起きにくいです。
最近はUnicodeが普及し滅多に見かけませんが、稀に疑わしい時があります。
文字コードとは取り扱う文字の集合とそのエンコード方式です。
文字集合の全ての文字に対して、それに割り当てるコードとそのコンピュータ内部での表現方法(エンコード方式)を決めます。
日本で使われる代表的な文字集合は以下の3種類です。
| 名前 | 説明 |
|---|---|
| ASCIIコード | 主に「半角」英数記号です。 |
| JISコード | 日本語の全ての文字です。(*1) |
| Unicode | 全ての言語の全ての文字です。 |
(*1)全ての文字
全ての文字と書きましたが、日本語の全ての文字ではなく、コンピュータで取り扱う目的で定めた日本語の標準文字です。Unicodeも同様です。世界中で使われている全ての言語・全ての文字と言う意味ではありません。
それぞれの文字集合に対して、大雑把にまとめると次のようなエンコード方式が決められています。
| 名前 | 主なエンコード方式 |
|---|---|
| ASCIIコード | ASCII |
| JISコード | JIS, Shift-JIS, EUC-JP |
| Unicode | UTF-7, UTF-8, UTF-16, UTF-32 |
エンコード方式は文字集合も定めますので、それぞれのエンコード方式ごとに含まれる文字集合も微妙に異なります。また、それぞれのエンコード方式はバージョンが複数あり、細かい差異があります。更に、UTF-16, UTF-32はバイトの並び順で更に細分化されています。
高度な日本語処理を行うようなプログラムではなく、各種の表示を日本語で行うような「普通」の日本語化を行うプログラムでは、次の文字コードがよく使われます。
| 名前 | 代表的な規格 | 説明 |
|---|---|---|
| ASCII | ANSI INCITS 4 | 7ビットで表現される最大128文字の半角の英数記号 |
| JIS | JIS X 0213, ISO-2022-JP | 1バイトコード:ASCII+半角カタカナ 2バイトコード:漢字と全角の英数記号 特殊文字(エスケープ・シーケンス)でコードを切り替える |
| Shift-JIS | CP932 | ASCIIとJISの2バイトコードの混在可能なマルチバイト文字 |
| UTF-16 | ISO/IEC 10646 | 1文字が2バイト。一部4バイト。 |
| UTF-8 | ISO/IEC 10646 | ASCIIと混在できるマルチバイト文字 |
これは、バーソナル・コンピュータの黎明期から存在しており、事実上現代の全てのコンピュータが対応している文字コードです。7ビットで英数字記号を表現します。
漢字に比べると形が単純な文字しかないため、ビットマップ・フォントなら、漢字より少ないピクセル数で形状を表現できます。そのため、漢字のほぼ半分の幅で表示されましたので、「半角文字」と呼ばれていました。
現在のフォントはプロポーショナル・フォント(文字の幅が文字毎に異なる。本の印刷等でも使われ読みやすいフォント)がほとんどですので、半角/全角と言う表現は適切ではないのですが、当記事のように文字コードの話を書く時には都合の良い表現なので使わせて頂いています。
コンピュータで漢字を取り扱うために決められたのですが、文字コードの切り替え用の特殊文字があるため扱いがたいへん面倒でした。例えば、文字列に含まれる文字数を数えたい時、特殊文字があるのでバイト数ではだめです。例えば、1文字削除する時、特殊文字を削除するべきかどうかの判定も複雑です。
そのため、後述のShift-JISが出現するとバーソナル・コンピュータで使われることはほとんどなくなりました。
JISコードで定められている全角文字をJISコードの半角文字とエスケープ・シーケンス無しで共存できるようにした頭の良い方法です。
半角文字は1バイト、全角文字は2バイトとたいへん分かりやすく、文字数を数えるのも簡単でした。(半角の文字数=バイト数)この特徴により、当時は全角の半分のサイズで半角文字を表示していたため、画面表示の計算も簡単になるのです。
ただし、Shift-JISは日本語にしか対応していません。中国語を表示したい時や韓国語を表示したい時、文字化けします。同様にドイツ語やロシア語のようにASCIIコードで表現できない文字を持つ国の言語を表示したい時も文字化けします。
Windowsコントロール・パネルの地域の設定にある「Unicode対応ではないプログラムの言語」の設定で決まります。その設定と異なる非Unicodeの文字コードで開発されたプログラムを走らせると、文字化けするのです。
また、昔はインターネットでWEBサイトを表示する時、よく文字化けしていたと思います。今も、古い古いサイトを表示すると文字化けすることがあります。それらのWEBサイトでShift-JIS等が使われ、かつ、使っている文字コードがページに記載されてなかった時に、自動判定に失敗した場合に発生します。
更に、ASCIIコードが全角文字コードに出現しないようにできればベストでしたが、それにはコードが足りないため、0x40未満のコードが現れないことを保証することが限界で、2バイト目には0x40~0x7eが出現します。そのため、先述したように、Shift-JISを理解しないライブラリにShift-JIS文字列でパスを渡してしまうと”Not Found”不具合が発生することがあります。
ASCIIコードで表現できない文字を表現したい国は少なくありません。中国や韓国等の「漢字」がある国は当然ですが、ヨーロッパのウムラウト(例えば、Ë等)がある文字や、アラビアの文字やロシアの文字など多数あります。それらをJISコードのように別のコード体系とし、エスケープ・シーケンスで切り替えるのは手間がかかります。
そこで、2バイトあれば全ての言語の文字を十分に表現できると考え、2バイトに世界中の文字集合を割り当てようとして発案されたものがUnicodeです。(現在は2バイトでは不足するため、最大4バイトが割り当てられています。)
Windowsもこれに対応し、Unicodeの2バイト版UTF-16をWindowsの標準的な文字コードとして採用しました。
Unicodeにより文字化けの恐怖から逃れることができるようになったのですが、ASCIIコードで十分な文字列しか必要としないライブラリは相変わらず1バイト文字列しか使えません。2バイト文字列に対応するためだけに、1バイト文字列で対応しているのと同等な機能をもう1セット提供する必要があり、手間ばかりかかる割にメリットが少ないからです。
そして、UTF-8です。これはASCIIコードとその他の文字コードを共存できることがメリットです。
ASCII文字コードに属する文字はそのままASCIIコードで表現されます。それ以外の文字は複数のバイトを用いて、かつ、どのバイトもASCIIコードと被らないコードのみを使用します。
その為、多くの日本語文字には3バイト使いますし、レアな文字では最大6バイト使います。
そして、従来のASCIIコードとの親和性が高く、共存が容易です。ASCIIコードで定義されている特殊文字は全てのそのままUTF-8でも同じコードですから、それらを処理するプログラムを大きく変更する必要がないのです。(ASCIIで未定義なコードに対してバススルーしているなら、そもそも変更不要な筈です。)
日本語文字列の密な加工を行うようなプログラムの場合はUTF-8は決してベストな選択ではないですが、日本語文字列は表示や連結程度であまり高度な処理を行わない多くのプログラムにとって、UTF-8はベストな選択と思います。
そして、XMLやJson等文字を取り扱うフォーマットのデフォルトやメジャーなコードがUTF-8になりつつありますので、それらを取り扱う時もあまり苦労しないで済みます。
gcc(Linux)とVisual C++(Windows)は、日本語の取り扱い方が異なります。
| 項目 | gcc | Visual C++ |
|---|---|---|
| std::wstringの1文字のサイズ | 4バイト | 2バイト |
| “char型文字列”の文字コードのデフォルト | UTF-8 | Shift-JIS |
| “char型文字列”の文字コードの変え方 | コンバイル・オプションと ソースの文字コード |
変更不可 |
| ソースのデフォルトの文字コード | UTF-8 | Shift-JIS |
msvcの場合、ソースの文字コードは通常Shift-JISですが、BOM付きのUTF-8でもビルト可能です。
このBOMはソース・コードの先頭にある3バイトの隠し文字で、UTF-8で記録されていることを示します。
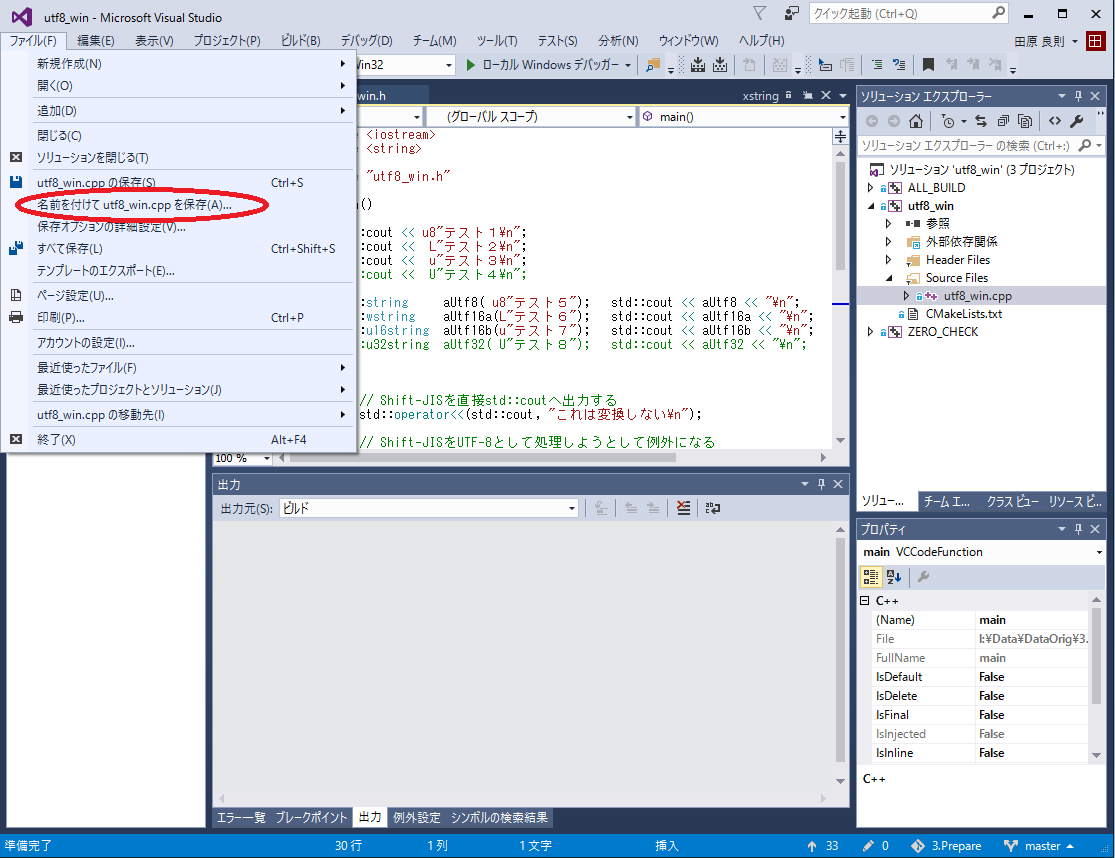
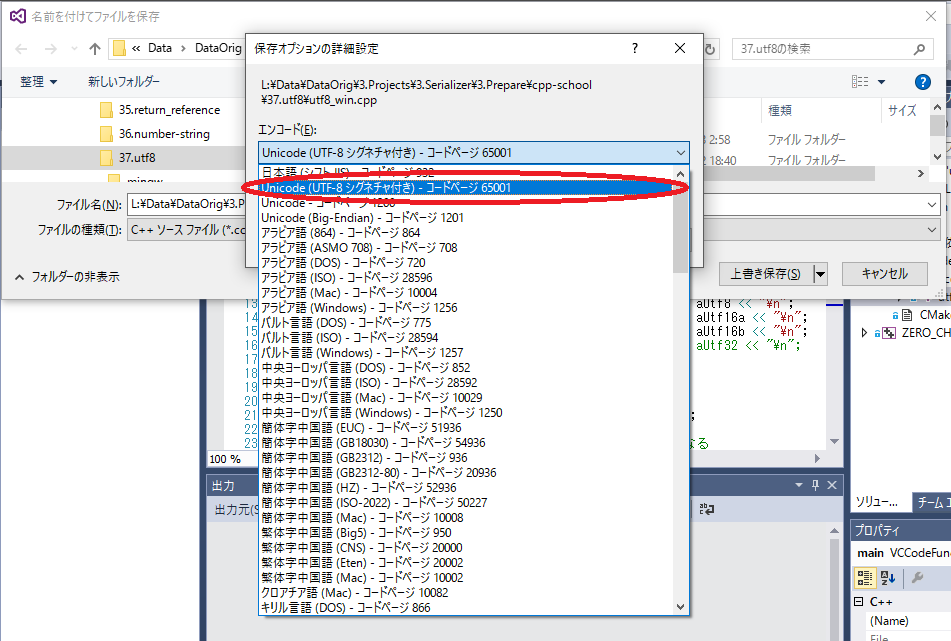
ファイルの文字コードの変更方法
もしも、gcc用のソース・ファイルをShift-JISで記述しているとコンパイル・オプションの指定が必要になるので面倒です。BOM付きのUTF-8はlinuxのgccでも特にオプションを指定することなくコンパイルできますので、ソースを共通化したい場合は、ソースをBOM付きUTF-8にすることがお薦めです。Visual Stduioで文字コードを変更する場合は、変更したいソース・ファイルを開いている状態でFileメニューから次のように操作します。
gccは既にデフォルトがUTF-8ですので、特に悩ましいことはありません。
しかし、Visual C++とWindowsは悩ましいです。
2017年5月9日修正
説明が不足していたので、下記を補いました。より分かりやすくなったと思います。
まず、Visual C++とWindowsの日本語用文字コードはUTF-16が基本ですが、未だにShift-JISが残っています。
- コマンド・プロンプトの表示
コマンド・プロンプトのデフォルトはShift-JISです。
chcp 65001と入力することでUTF-8に切り替わりますが、まともには動作しません。(元のShift-JISへ戻すにはchcp 932です。) -
Visual C++の文字列定数(”char型文字列”です)
通常の文字列定数(”例えばこれ”)はShift-JISコードです。ソース・ファイルをUTF-8で保存しても文字列定数の文字エンコードはShift-JISです。Visual C++はなかなか頑固です。
なお、C++11でu8″文字列”が規定されています。これはu8指定した文字列定数をUTF-8でエンコードするという意味です。Visual C++ 2015以降で対応されています。
非公開な#pragmaがあります。
#pragma execution_character_set(“utf-8”)を使うと”char型文字列”のエンコードがUTF-8に変わります。しかし、非公開だけあって完全には動作しませんでした。解っている範囲では①Visal Stduio 2008は非サポート、②本来\uXXXXのような形式でUnicodeのコードで文字を直接指定できますがこれはダメでした。他にも問題が潜んでいる可能性もあります。
ですが、最近公開されました。 もしかすると、このu8″”文字列対応に伴い解消している可能性もあります。
先述したように、他の言語用に設定されたWindowsで動作させると文字化けします。
日本語Windowsでのみ動作するプログラムならば、Shift-JISを使うことも選択肢に入ると思います。
しかし、現代は国際化の時代ですので、国際化に慣れるためにもなるべくShift-JISを使わない方が好ましいです。
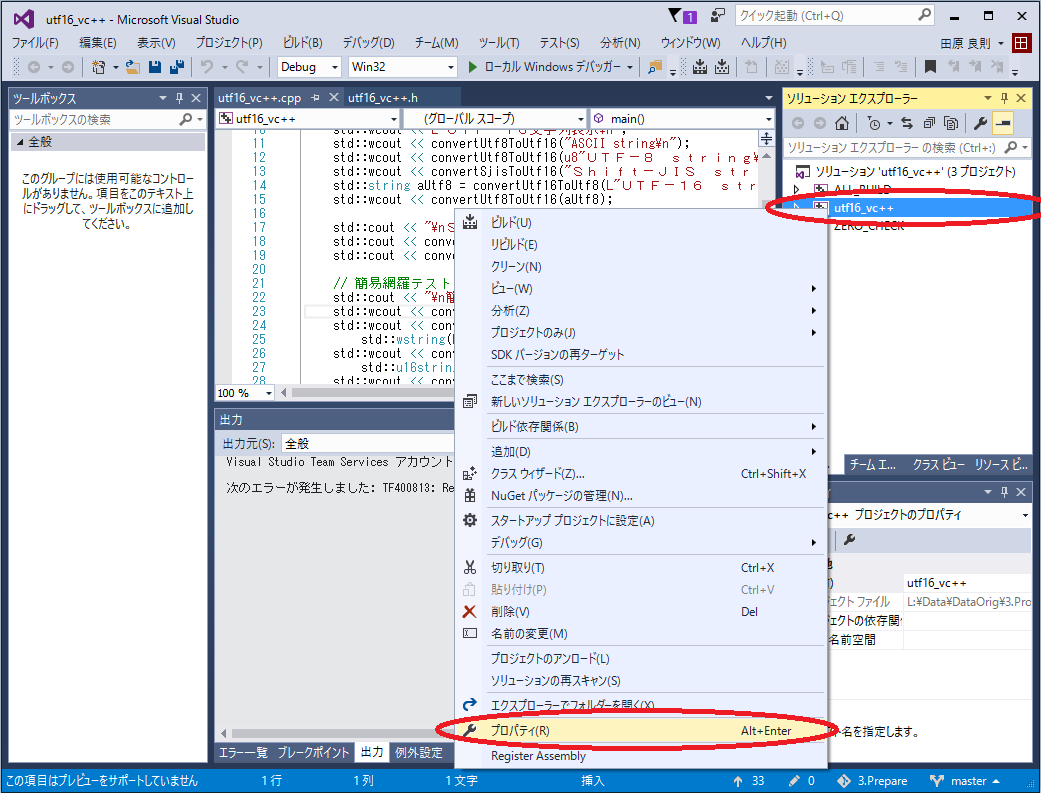
Visual Studioの設定を変更する方法
Visual StudioはデフォルトではUTF-16を用いますので、これをShift-JIS(日本語Windowsの場合)へ変更するには、下記手順で行います。
1. プロジェクトのプロパティを開く
2. 構成(C)を「全ての構成」とし、構成プロバティを「全般」 → 文字セットを「マルチ バイト文字セットを使用する」を選択する
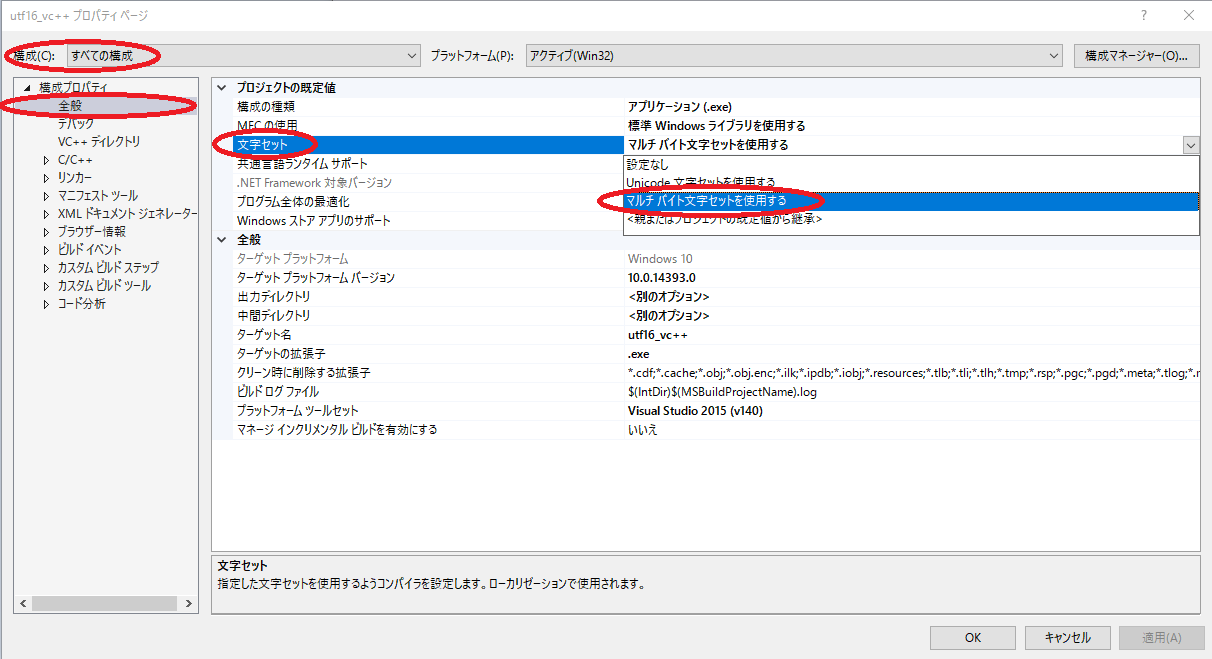
Visual Studioのデフォルトですし、Windows専用プログラムの場合はこちらが好ましいと思います。ただし、下記のような問題は発生します。
- コマンド・プロンプトへ日本語出力がやりづらい
デバッグ用に出力することもあると思います。std::wcout << L"日本語\n";のようにして出力するのでずか、デフォルトでは何も表示されません。ちょっとおまじないが必要です。 -
char型文字列しか扱わないライブラリとの共存に手間がかかる
エラー・メッセージを作る時、ライブラリへ与えた文字列をメッセージ内に含めることも少なくないですが、その時UTF-16との変換について考慮することが必要です。
この問題を軽減するため、ASCII文字列をUTF-16文字列へ変換するツールを用意しておくと好ましいです。(後述)
マルチ・プラットフォーム対応の「高度な日本語処理を行わないような普通」のプログラムを開発する時は、UTF-8を中心的な文字コードにすることがお薦めです。
(この場合もVisual Stduioの設定は2-4-3.と同じくデフォルト(Unicode文字セットを使う)のまま変更しないで下さい。)
- LinuxではUTF-8がデファクト・スタンダードですので、よりソースを共通化しやすいです。
#ifでプラットフォーム毎の分岐が大きく減ります。 -
char型文字列しか扱わないライブラリとの共存が容易です。
エラー・メッセージを作る時、ライブラリへ与えた文字列をメッセージ内に含めることも少なくないですが、その時UTF-16との変換を考慮しなくて良いので楽です。
ただし、Windows APIを呼び出す部分は専用コードを書くことになりますから、そこでUTF-8とUTF-16を変換することになります。UTF-8とUTF-16の変換関数を用意しておけば軽減できます。(後述)
また、Windowsのコマンド・プロンプトへUTF-8文字列を出力すると文字化けしますので、デバッグ等でコマンド・プロンプトを使う場合にちょっとだけ面倒です。
こちらもちょっとしたツールを用意すると問題を大きく軽減できます。(後述)
Visual C++でUTF-16やUTF-8を使うときのちょっとしたコード変換ツールを作ってみました。
ご自由に使って下さい。(ただし、
私からの保証はありません
ので、ご自身の責任でお願いします。)
C言語で作ると結構手間がかかりますが、C++11ならたいへん楽です。
Visual Studio 2015でビルドできます。
Visual C++専用ツールですので、gccではビルドできません。
MinGWならビルド出来る可能性はありますが、未確認です。
Shift-JISとUTF-16、UTF-8とUTF-16間の相互変換を行います。UTF-8はASCIIをカバーしていますので、ASCI文字列をUTF-16へ変換する時はconvertUtf8ToUtf16()を使って下さい。
また、std::wstring、std::u16string、wchar_t、char16_tは全てUTF-16でエンコードされた文字列が設定されていることを仮定しています。
ヘッダ・オンリですので、utf16_vc++.hをインクルードすれば使えます。(utf8_vc++.hをインクルードしているのでutf8_vc++.hも同じフォルダにおいてください。)
コマンド・プロンプトへの文字列出力がUTF-8, UTF-16であると仮定して、Shift-JISへ変換して出力するようにoperator<<(std::ostream&, …)をオーバーロードします。
もし、Shift-JIS文字列を出力しようとすると、それをUTF-8と解釈してUTF-16へ変換しようとし、かなりの率で失敗します。変換できなかった時はrange_error例外が発生します。
ヘッダ・オンリですので、utf8_vc++.hをインクルードすれば使えます。
2019年1月22日 追記:
Windows 10のコマンド・プロンプトの仕様がいつのまにか変わっているようです。
デフォルトではShift-JIS文字列が適切に表示されません。
コマンド・プロンプト・ウィンドウの左上のシステム・コントロール・アイコンをクリックして出てくるメニューからプロパティを選択し、「レガシ コンソールを使う」をチェックしてコマンド・プロンプトを再起動すると表示されるようになります。
もしくは、std::cout等で出力する前に、std::locale::global(std::locale(“japanese”)); しておくと新コンソールでも化けないようです。詳しい事情はまだ把握できていません。ご存知の方がいらっしゃいましたら、コメントいただけるとありがたいです。
C++による日本語プログラミング環境は、残念ながら過去のシガラミもあり、すっきり「これが正解」と言うプログラム方法が決まっていません。アプリケーションにより複数の選択肢があり、しかも、処理系によって選択できる選択肢が異なる状況です。(LinuxではUTF-8が優勢です。Windowsが特に悩ましいです。)
それらの歴史的な経緯と現在使われている文字コードの特徴について解説しました。
高度な日本語処理を行うアプリケーションを開発するにはとても足りませんが、メッセージ表示等を日本語化するための最小限の知識を解説できたと思います。
また、Visual C++で日本語を扱う際の便利ツールも提供してみました。もし良かったらお使い下さい。
Unicode対応ですし、Shift-JISと明示的に指定しているわけでなく、Windowsのコントロール・パネルの地域に設定されている非Unicode時の言語設定に従った処理となっていますので、恐らく他の国の言語でも動作することを期待できます。(実際に走らせてないので確認出来ていません。)
来週は、プリプロセッサについて少し突っ込んだ使い方等を解説したいと思います。
プリプロセッサは、テンプレートと同様一種のメタ・プログラム(プログラム・コードを生成するプログラム)としても働きますので、意外に便利です。お楽しみに。

はじめまして、teratailから飛んできましたw
交換機やらフィルターサーバやら単発・組み込みばかりやってきて最新の知識には疎いので、(既に引退してますが)こういったサイトは、大変ありがたいです。・・・c++は、ますます難しくなって(私の頭では)なかなか追いつけません。
今後ともよろしくお願いします。
CatEye様、コメントありがとうございます。
やはりコメントって嬉しいものですね。ありがたいと言って頂けると励みになります。
時々分かりにくい部分もあるかと思いますが、頑張って更新していきますので、是非お付き合い下さい。
これからもよろしくお願い致します。
Pingback: JNAでC++に渡した文字列が文字化けしてしまう場合 | IT技術情報局