
こんにちは。田原です。
プリプロセッサはテキストを加工するもう一つの言語です。これがソース・ファイルを前処理(プリプロセス)し、コンパイラが加工されたソースをコンパイルします。プリプロセッサもテンプレートと同じく一種のメタ・プログラミング・ツール(プログラム・コードを生成するプログラム)です。コンパイル時に処理するので実行時間は0なので高速です。テンプレートより機能が単純なので通常の使い方は簡単です。ただし、テキスト処理特有の落とし穴もいくつかあります。今回はこのプリプロセッサについて解説します。
ソース・コードの一部を条件によって切り替えたい場合があります。
そのような時に用いるのが、#if(#ifdef, #ifndef)~#else~#endifプリプロセッサ命令です。
条件付きコンパイル用のプリプロセッサ命令には以下のものがあります。
| プリプロセッサ命令 | 意味 |
|---|---|
| #if 条件式 | 条件式が成立したら、#else, #elif, #endfの内最初に現れたものまでの文をコンパイルする。そうでない時に、#elseがあれば#else以降をコンバイルする、#elifがあればelifに従って処理する。 |
| #ifdef シンボル | シンボルが定義されていたら、以下同文。 |
| #ifndef シンボル | シンボルが定義されていなかったら、以下同文。 |
| #elif 条件式 | 条件式が成立したら、以下同文。 |
| #else | 条件が非成立時にコンパイルするコードの始まり。 |
| #endif | #if命令(#ifdef, #ifndef含む)の終わり。 |
条件式に書けるものは、整数型定数を用いた式です。(変数やC言語/C++関数は一切使えません。)
整数型定数(定数は全て右辺値です)に対して使える各演算子(算術、ビット、論理、比較)を使うことが出来ます。
C++のif文と良く似ていますが、以下の点異なります。
- 記述できる条件式が異なる。
- 成立しなかった方は、コンパイルされない。
例えば、カレンダー処理用の標準ライブラリがあるのですが、その中にメジャーなコンパイラ(Visual C++, gcc)に受け入れられていない物が有ります。gmtime(), localtime()のスレッド・セーフ版(*1)であるgmtime_s(), localtime_s()です。(C++の標準ライブラリには時刻を取り扱う
(*1)スレッド・セーフ版
元のlocaltime()等はマルチスレッドでそのまま使うとデータ破壊が低確率で発生します。その対策のため、排他制御しつつ結果のコピーが必要です。これらの関数の仕様が適切であればこれらは本質的には不要な操作であり、その仕様を見直したものがスレッド・セーフ版です。(C言語の標準ライブラリが策定された時代は「マルチ・スレッド」は一般的ではなく考慮されなかったのだろうと思います。)
localtime()のスレッド・セーフ版の例:
| 定義元 | 定義内容 |
|---|---|
| C11 | struct tm *localtime_s(const time_t * restrict timer,struct tm * restrict result); |
| Visual C++ | errno_t localtime_s(struct tm* _tm,const time_t *time); |
| gcc | struct tm * localtime_r (const time_t *time, struct tm *resultp); |
このような問題を回避する際などに#ifdef等の条件付きコンパイルを良く用います。(もちろん、後述のインクルード・ガード等、他のケースでも使います。)
#include <iostream>
#include <iomanip>
#include <time.h>
#ifdef _MSC_VER
struct tm* localtime_r(const time_t* time, struct tm* resultp)
{
if (localtime_s(resultp, time))
return nullptr;
return resultp;
}
#endif
int main()
{
time_t now = time(NULL);
struct tm local_tm;
localtime_r(&now, &local_tm);
std::cout << std::setw(4) << std::setfill('0') << local_tm.tm_year+1900 << '/'
<< std::setw(2) << std::setfill('0') << (local_tm.tm_mon + 1) << '/'
<< std::setw(2) << std::setfill('0') << local_tm.tm_mday << " "
<< std::setw(2) << std::setfill('0') << local_tm.tm_hour << ':'
<< std::setw(2) << std::setfill('0') << local_tm.tm_min << ':'
<< std::setw(2) << std::setfill('0') << local_tm.tm_sec << "\n";
return 0;
}
第10回目で説明したように、コンパイルは「コンパイル単位」毎に行われ、1つのコンパイル単位は大本のソース・ファイルから#includeで他のファイルがインクルードされ、1つのファイルへまとめられたものです。
例えば、main.cppが
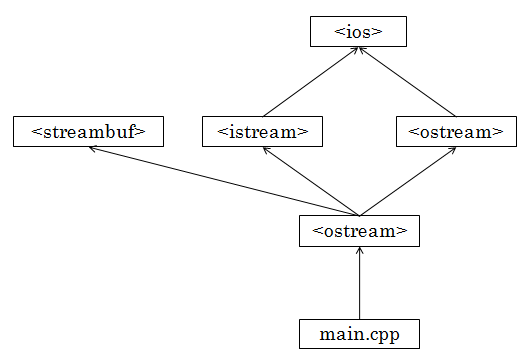
このような時に問題になることがあります。
<ios>は<istream>と<ostream>の2つのファイルからインクルードされています。
なので、何の対策も行わないと、<ios>で定義されているシンボル等が2回定義されてしまい、多重定義エラーになります。
かと言って、とがをインクルードしない場合、やをインクルードするファイル(この場合は)が
そのためには、プログラマは自分が使いたいヘッダが依存しているヘッダを把握して、それらを先にインクルードする必要があり、非常に手間がかかります。
そこで、「インクルード・ガード」というテクニックが普遍的に使われています。多重定義を避ける必要があるファイルではほぼ100%と言って良いと思います。
基本は以下のようなテクニックです。
#ifndef SAMPLE_H #define SAMPLE_H // sample.hの中身 #endif // SAMPLE_H
SAMPLE_Hシンボルが定義されていなければ、SAMPLE_Hを定義してsample.hの中身をコンパイルします。
2回目以降、sample.hがインクルードされると、SAMPLE_Hが定義されているため、#ifndefによりコンパイルされないのです。
若干問題があります。
- SAMPLE_Hシンボルが他のファイルで定義されるとうまく動作しない
先にインクルードされた方のみコンパイルされます。
そこで、他で定義されないようなシンボルにするため、プリフィクス/ポストフィクスを付ける、プロジェクト・ルートからのバス名も含める等の工夫が有効です。 -
ヘッダをコピーペした時、ガード用シンボルの修正を忘れる
やらかすと結構悩みます。確かにインクルードしているのに中身が定義されないのです。
更に、コピペ元のヘッダと一緒にビルドすることが少ない場合、発覚が遅れるのでかなり悩みます。
後者の問題に有用な仕組みがあります。`#pragma once’です。
ヘッダ・ファイルの先頭に書いておくだけで上記のインクルード・ガードと同じ働きをします。
そして、シンボル名を決める必要がないのでお手軽です。
標準規格では規定されていませんが、多くのコンパイラがサポートしているので使える場合が多いです。
Visual C++とgccは共にサポートしています。
#defineでシンボルを定義できます。そのシンボルのことを「マクロ」と呼びます。
マクロ展開
マクロには引数を指定できるものと指定できないものがあります。
次のものは両方ともマクロです。前者は引数なし、後者は引数ありです。
#define MACRO 12345 #define FUNCTION(x) (x*5)
後者を定義する時、マクロ名と(の間にスペースをあけてはいけません。続けないと引数無しマクロとして解釈されてしまいます。
マクロの命名規則について
マクロはC++の変数や関数とは全く異なります。ソース上の文字列を置き換えるだけで、そのような変数や関数がメモリ上に存在するわけではありません。そのためマクロを使う時、意外な振る舞いをする場合があります。(3-2.参照)
そこで、命名規則を変えてひと目で分かるようにする強い習慣があります。マクロ名は全て大文字とし単語の区切りを `_`(アンダーライン)を使います。例えば、`THIS_IS_A_MACRO`のような感じで命名します。逆にマクロでない名前には、全て大文字の名前を使いません。この習慣に従わなくてもコンパイラはエラーも警告も出しませんし、全ての人が従う習慣ではありませんが、かなり強い習慣です。皆さんもできるだけこの習慣を採用されることをお勧めします。
#defineで定義したマクロを書くと書いた位置に定義した内容がそのまま展開されます。
また、定義時にマクロ名の後ろに何も書かなった場合、そのマクロを展開する際に単に消えてしまいます。
#define MACRO 12345 #define FUNCTION(x) (x*5) #define EMPTY std::cout << MACRO << "\n"; std::cout << FUNCTION(2) << "\n"; EMPTY;
は、プリプロセッサにより、次のように展開されます。
std::cout << 12345 << "\n"; std::cout << (2*5) << "\n"; ;
「マクロ」と言う呼び方について
Excel等のマクロとはかなりイメージが異なるので違和感があるかもしれません。
Excelは影も形もなかった大昔からアセンブラには「マクロ」がありました。
アセンブラの「マクロ」はプログラマが定義できるある種の簡易言語でした。
C言語のマクロは正にそれと同様な機能を持っています。
Excel等のマクロも「簡易言語」としての位置づけでマクロと呼ばれているのだと思います
マクロは1行で定義します。しかし、C++には行を継続する機能があります。行の最後に¥マークを置くと次の行が¥マークの行に繋がり、1行として処理されます。
#define LONG_LONG_MACRO(dParameter0, dParameter1) \
do \
{ \
std::cout << dParameter0 << std::endl; \
std::cout << dParameter1 << std::endl; \
} \
while(0)
LONG_LONG_MACRO(123, 456);
複数行を書く時、少し注意事項があります。
- ¥マークの後ろには改行しか書いてはいけません。
何か書くとエラー(Visual C++)や警告(gcc)になります。 -
//コメントを¥マークで継続すると次の行はコメントでないように見えてコメントになってしいます。
// 次の行は実行されません。これが原因です。→ \ std::cout << "This line is not executed.\n"; std::cout << "This line is executed.\n";
Visual C++, gcc共に警告を出してくれますので、警告に注意しておけばまず大丈夫です。
Wandboxで試してみる
継続マークを使って複数行にしている時にコメントしたい場合は、/* */形式のコメントを使えば良いです。
#define MULTI_LINE_MACRO(x) \
/* This is a multi line macro.*/ \
std::cout << x << "\n"
#define文の中では、#演算子と##演算子が使えます。
仮引数の前に#を付けることで、実引数の文字列へ変換されます。
また、仮引数の前、もしくは、後ろへ##を付けることでその前後の文字列と連結します。
int FooBar=123; #define FOO_CAT(x) (Foo ## x) std::cout << FOO_CAT(Bar) << std::endl; #define CAT_BAR(x) (x ## Bar) std::cout << CAT_BAR(Foo) << std::endl; #define STRINGIZE(x) #x std::cout << STRINGIZE(FooBar) << std::endl;
#undef マクロ名で、そのマクロを消去できます。
#define FOO 123 // ここではFOOを使うことができる std::cout << FOO << "\n"; #undef FOO // ここてはFOOを使えない // ↓はコンパイル・エラーになる // std::cout << FOO << "\n";
コンバイル開始時にプリプロセッサによって既に定義されているマクロがあります。
比較的よく使うものは以下の通りです。
標準化されているもの
| マクロ名 | 意味 |
|---|---|
__FILE__ |
コンパイル中のソース・ファイル名 |
__LINE__ |
LINEが記述されているソース・ファイル先頭からの行数 |
__DATE__ |
現在のプリプロセッサが起動した日付 |
__TIME__ |
現在のプリプロセッサが起動した時刻 |
処理系依存のもの
| マクロ名 | 意味 |
|---|---|
| _MSC_VER | Visual C++の時定義されており、そのバージョン番号となる |
_WIN32 |
Windows上で動作するオブジェクトをコンパイル中定義されている場合が多い。 Visual C++, MinGWでは定義されている |
| __GNUC__ __GNUC_MINOR__ __GNUC_PATCHLEVEL__ |
gccの時定義されており、そのバージョン番号となる |
他にも処理系依存の定義済みマクロは多数あります。お使いのコンパイラのマニュアルを必要に応じてご確認下さい。
例えば、_WIN32が定義されていないようてWindowsバイナリを生成するコンパイラもあるかも知れません。
そのような時は、CMakeLists.txtのadd_definitionsで対処できる場合が多いです。
gccのWindows版であるMinGWでは_WIN32は定義済みマクロですが、もしも、定義されていなかった場合は、CMakeLists.txtで次のようにすることで対処できます。
(前略)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
if(WIN32)
add_definitions(-D_WIN32)
endif()
endif()
(後略)
多くのサイトや書籍で注意事項として記載されています。
まず、マクロは本当に文字列を展開しているだけです。そのシンボルは変数や関数としての役割を担いません。
#define FUNC(x) x+5 std::cout << FUNC(10)*20 << std::endl;
とあった場合、FUNC(10)が15となり、それに20をかけるので、300が出力されることを期待すると思います。
しかし、マクロは文字列の展開ですので、上記ソースは次のように展開されます。
std::cout << 10+5*20 << std::endl;
計算すると110になりますので、出力されるのは110です。
対策としては、マクロを数式として定義する時、()で括れば良いです。
#define FUNC(x) (x+5) std::cout << FUNC(10)*20 << std::endl;
展開すると、
std::cout << (10+5)*20 << std::endl;
となりますから、見かけ通りの動作になります。
また、マクロの引数を渡す時、その引数に「副作用」のある式を渡すとハマりやすいです。
大変良く使われる例が有ります。
#define MAX(a, b) ((a>b)?a:b) int x=10; int y=20; std::cout << MAX(++x, ++y) << std::endl; std::cout << "x=" << x << " y=" << y << std::endl;
は、次のように展開されます。
int x=10; int y=20; std::cout << ((++x>++y)?++x:++y) << std::endl; std::cout << "x=" << x << " y=" << y << std::endl;
ということは、(++x>++y)が成立すると++x、そうでないと++yが評価され値が取り出されます。
つまり、(++x>++y)と、++xもしくは++yにより、xかyのどちらかは2回インクリメントされます。
それは十中八九、マクロを使った人の意図とは異なる動作でしょう。
この場合は、マクロの引数に副作用のある式を渡さないよう、MAXマクロを使う人が気をつけるしかありません。
そのためにもマクロであることがひと目で分かるよう、先述した命名規則通り、マクロ名は全て大文字を使うことがお薦めです。
マクロには複数の文を指定することも可能です。
#define SETUP(x, y) x.data=y; x.is_valid=true;
struct Foo
{
int data;
bool is_valid;
Foo() : data(0), is_valid(false) { }
};
Foo foo;
SETUP(foo, 100);
のような使い方をすることがあるでしょう。
SETUPマクロの意味は、構造体fooのdataへ値を設定し、それが有効であると記録しています。
しかし、これが次のよう使われた時が困ります。
Foo foo; if (cond) SETUP(foo, 100);
condがtrueの時だけ、fooに100を設定し、is_validをtrueにしたつもりです。
しかし、上記ソースは次のように展開されます。少し分かりやすくするため、改行を調整しました。
Foo foo; if (cond) foo.data=100; foo.is_valid=true;
condがfalseだった時、foo.dataに値を設定しないまま、foo.is_validがtrueになってしまいます。なかなか痛いバグになりそうです。
定番の対策があります。ちょっと気持ち悪く見えますが、次のようにマクロを定義することです。
#define SETUP(x, y) do{x.data=y; x.is_valid=true;}while(false)
すると、次のように展開されます。
Foo foo;
if (cond) do{foo.data=100; foo.is_valid=true;}while(false);
つまり、condが成立した時のみ、foo.dataとfoo.is_validが設定され、while(false)なので直ぐにdoループを抜けるのです。
ちなみに、do-whileを本来の用途と異なる使い方をしているので気持ち悪いですから、次のように定義することも考えられます。
#define SETUP(x, y) {x.data=y; x.is_valid=true;}
これは、次の使い方をした時コンパイル・エラーになります。
Foo foo;
if (cond)
SETUP(foo, 100);
else
do_something();
これを展開すると次のようになります。
Foo foo;
if (cond)
{x.data=y; x.is_valid=true;};
else
do_something();
}の後ろに;が残ってしまうのです。if文はそこで終わりますので、elseに対応するif文が存在しないため、エラーになります。
しかし、do-while定義であれば、次のように展開されます。
つまり、if文のthen節にdo-while文が1つだけ書かれているので問題なくコンパイルに通るのです。
Foo foo;
if (cond)
do{x.data=y; x.is_valid=true;}while(false);
else
do_something();
#undefがあるので、マクロも一種の変数として使えそうに見えます。
#define FOO 1
:
#undef FOO
#define FOO 2
:
このようにベタ書きなら一種の変数のように使えます。
しかし、このFOOへの代入処理を「サブルーチン」として定義しようとしてもできません。
次のように書けばできそうに見えますね。
#define SET_FOO(x) \
#undef FOO \
#define FOO x
しかし、#define文の中の#は#演算子として解釈され、そして「仮引数の前でないエラー」となり、コンパイルできません。
これはどう頑張ってもプリプロセッサの範疇では解決できません。残念ですが、諦めるしかありません。
マクロはソース・コードを修正します。ですので、コンパイラはマクロ展開する前のソースを把握できません。
そして、デバッグ用の情報を生成するのは、コンパイラとリンカです。
ということは、マクロ展開前の情報をデバッグ情報として残すことができないのです。
#define PI 3.14
:
std::cout << 2*PI*r << std::endl;
のようなコードがあった時、PIが3.14であることをデバッガは把握できないのです。
Visual StudioやCode::BlocksのようなIDEを使ってデバッグしている時、PIの値が分からないってなかなか辛いです。
デバッグ中ですから、PIが間違っているかも知れないのです。なのにその値を確認できないわけです。
ですので、マクロを使わないで良い場合はマクロを使わないことが強く推奨されます。
上記の場合は、次のようにして「定数」を定義します。
これにより、プログラム用メモリにpiと言う名前が付けられて保存され、その情報をコンパイラは知っているのでデバッガへ伝達され、IDEでデバッグ実行中に内容を観察できるようになるのです。
const double pi=3.14;
:
std::cout << 2*pi*r << std::endl;
C言語時代から連綿と使われ続けているプリプロセッサについて解説しました。
プリプロセッサは、ソース・コードを書き換える仕組みですので、「メタ・プログラミング」ツールでもあります。「メタ・プログラミング」とはプログラムを生成/修正するプログラムのことです。
C++には「テンプレート」と言うたいへん強力な「メタ・プログラミング」ツールが導入されています。ですので、前節でも書いたようにテンプレートでできることはなるべくテンプレートを使った方が良いです。しかし、マクロはソース・コードを修正する機能を持つという性質から完全に置き換えることはできません。
その代表は、#演算子です。例えば、変数をマクロに与えることで、変数とその変数名の両方を同時に取り出せます。
#define PRINT(var) std::cout << #var "=" << var << std::endl int x=10; PRINT(x); double y=123.456; PRINT(y);
テンプレートは「変数名」にアクセスすることはできませんので、このような処理は絶対にできません。
このようにマクロでないとできないこともそこそこ残っていますので、マクロのことも覚えてやって下さい。
さて、次回からいよいよC++のC++らしい部分であるクラス(オブジェクト指向プログラミング)について解説を始めたいと思います。
