
こんにちは。田原です。
C言語の明示的な型変換は1つしかありません。問答無用に変換するので使い方を誤りやすくバグの元になり勝ちです。それに比べC++の明示的な型変換は危険なものが別れているためそれを使わないよう避けておけば比較的安全です。
また、その一つのdynamic_castは遅いと聞くので測ってみたところ、面白い結果が出ましたので報告します。
1.まずは暗黙の型変換
C++は明示的に型を指定して変数や定数の型を変換する場合と、暗黙的(自動的)に変換される場合の2つがあります。まずは暗黙的な変換について簡単に説明します。(詳しい説明は複雑ですので、入門講座では扱いません。)
1-1. いつ暗黙の型変換が発生するのか?
関数に渡される時と演算される時に暗黙の型変換(自動変換)が発生します。
例えば、short x=10; foo(x);のように関数fooへshort型変数xが渡される時やx+1のように演算される時です。
1-2. どんな変換が発生するのか?
- 関数へ渡される時は仮引数の型へ実引数が変換されます。
例えば、void foo(short x);の時、char y=10; foo(y);とするとyはshort型へ変換されてからfoo()へ渡されます。
代入文もこれと同じです。右辺の値が左辺の型へ自動的に変換されて代入されます。 - 演算される時は、
- int型で表現できる型は一旦全てint型へ変換されます。
例えば、short x=10; short y=20;の時、x + yは、xとyがそれぞれint型へ変換されてから足し算され、結果もint型となります。
対象となる型は「char, signed char, unsigned char, short, unsigned short」です。 - int型で表現できない型はより精度の高い方へ変換されます。
例えば、int a=10; double b=20.0;の時、a + bは、aが一旦double型へ変換されてから足し算され、結果はdouble型となります。
- int型で表現できる型は一旦全てint型へ変換されます。
「演算する時、精度の高い方へ合わせられる」ことを把握しておけば概ねOKですが、C++にはオーバーロードがあります。これがややこしいです。
オーバーロードは引数の型が異なる同じ名前の関数を定義でき、その名前の関数へ渡す引数の型により、実際に呼び出される関数が変わります。
ですので、例えばshort同士の足し算でも結果がint型に変わるため、int型を受け取るオーバーロード関数が呼ばれます。
つまり、「演算する時、int型より小さい時はint型へ変換される」ことも把握しておいた方が良さそうです。
#include <iostream>
void foo(int x)
{
std::cout << "foo(int x) x=" << x << "\n";
}
void foo(short x)
{
std::cout << "foo(short x) x=" << x << "\n";
}
int main()
{
short a = 10;
short b = 20;
foo(a);
foo(b);
foo(a+b);
}
を実行した時、foo(a);とfoo(b);は演算しておらず そのままa, bが渡されるため、foo(short x)が呼ばれます。この2つは問題ないと思います。
さて、foo(a+b);では、どちらが呼ばれるでしょうか?
Wandboxで答を見る
この性質を使ってちょっとだけ便利なテクニックがあります。
std::coutにchar型変数を出力すると文字として出力されます。大抵の場合はそれで良いのですが、時として文字ではなく「文字コード」を見たい場合があります。そんな時、0を足し算しても値は変化しませんが、上記の変換によりint型へ変換されます。int型は値が出力されますので晴れて文字コードを出力できます。
#include <iostream>
int main()
{
char c='1';
std::cout << c << "\n";
std::cout << c+0 << "\n";
}
1 49
文字’1’の文字コードは0x31です。10進数では49です。
前者の出力では、char型変数が文字として出力されるため、文字の’1’が出力されます。
後者の出力では、0を加えてint型へ変換して出力すれるため、数値の49が出力されます。
1-3.引数が1つのコンストラクタ
引数が1つだけのコンストラクタは、実はちょっと特殊です。そのままですと暗黙の型変換に使われるからです。
1-3-1.暗黙の型変換とその禁止
暗黙の型変換は自動的に行われるので時として想定外の自動変換が発生し苦労します。
私自身は関数のオーバーロードで苦労したことがあります。
先にも書いたようにオーバーロードは実引数として与えた値の型で実際に呼び出す関数が決定されます。
その時、複数の関数が該当したら「曖昧で呼び出せない」というコンパイル・エラーになりコンパイルできません。
例えば、以下は曖昧エラーになります。
#include <iostream>
void foo(float x)
{
std::cout << "foo(float x) x=" << x << "\n";
}
void foo(double x)
{
std::cout << "foo(double x) x=" << x << "\n";
}
int main()
{
foo(123);
}
定数123は型を特に指定していないのでint型になります。
foo()は2つ定義されてますのでコンパイラはどちらを呼び出すべきか判断するため、全てのfoo()のオーバーロードに対して呼び出せるか試みます。
- 実引数のint型をfloat型へ暗黙の変換をすることでfoo(float x)を呼び出せます。
- 実引数のint型をdouble型へ暗黙の変換をすることでfoo(double x)を呼び出せます
つまり、呼び出せるfoo()が2つ見つかったのです。しかし、どちらを呼び出すべきかコンパイラが判断できないので「曖昧」になります。
同様に次のコードも「曖昧」になります。
##include <iostream>
class bar
{
int mData;
public:
bar(int iData) : mData(iData) { }
int get() { return mData; }
};
class baz
{
int mData;
public:
baz(int iData) : mData(iData) { }
int multi(int x) { return mData*x; }
};
void foo(bar x)
{
std::cout << "foo(bar x) x=" << x.get() << "\n";
}
void foo(baz x)
{
std::cout << "foo(baz x) x=" << x.multi(2) << "\n";
}
int main()
{
foo(123);
}
foo()は2つ有るので先述したのと同様、全てのfoo()のオーバーロードに対して呼び出せるか試みます。
barとbazには両方共int型を1つ引数に取るコンストラクタがあるため、これらが暗黙の型変換に使われます。
- 実引数のint型をbar型へ暗黙の変換をすることでfoo(bar x)を呼び出せます。
- 実引数のint型をbaz型へ暗黙の変換をすることでfoo(baz x)を呼び出せます
つまり、呼び出せるfoo()が2つ見つかりました。しかし、どちらを呼び出すべきかコンパイラが判断できないので「曖昧」になるのです。
このような状況を回避するため、コンストラクタを暗黙の型変換に使っていはいけないことを指定できます。explicitと書きます。例えば、上記のサンプルのbarのコンストラクタにexplicit指定するには次のように書きます。
explicit bar(int iData) : mData(iData) { }
これによりbar(int iData)コンストラクタはint型をbarへ「暗黙の型変換」する時には使われなくなります。しかし、baz型へは相変わらず使ってはいけない旨を指定していないため変換できます。従って、この場合、foo(baz x)が呼ばれます。
1-3-2.関数のオーバーロードについて補足
1-3-1.の例では2つのfoo()を呼び出せるため、「曖昧」になると書きましたが、実はもう少し複雑です。
複数のfoo()を呼び出せる場合でも、優先順位が付いていることがあります。
暗黙の型変換をせずに呼び出せる関数は、暗黙の型変換をしないと呼び出せない関数より優先されます。
優先される関数が1つしかない場合、「曖昧」にはなりません。
#include <iostream>
void foo(float x)
{
std::cout << "foo(float x) x=" << x << "\n";
}
void foo(double x)
{
std::cout << "foo(double x) x=" << x << "\n";
}
int main()
{
foo(123.0);
}
先述の例で、foo(123.0);で呼び出してみました。定数123.0はdouble型になります。
従って、foo(double x)は暗黙の型変換なしに呼び出せます。そして、そのようなものは1つしかないため、曖昧にならずコンパイルに通ります。
1-3-3.explicitはつけるべきか?
上述のオーバーロードのケースのように必要な時には当然つけますし、暗黙の型変換をしたい場合には当然つけません。これは最優先です。
そのどちらでもない時は、どうしますか?という話です。
explicitを付けなくても、どんなコンストラクタがあるのかきちんと確認してコーディングすれば特に必要はないですが、いちいち確認するのも手間なので記憶に頼ってコーディングする時もあると思います。
そのような時のポカミスを防ぐために、どちらでも良い時はできるだけexplicitをつけておくことをお勧めします。explicitと書く手間がちょっとあるだけで大きなデメリットはないですから、そのような場合はできるだけコンパイラのポカミス防止機能を使った方が生産性は上がりますのでお薦めです。
2.明示的な型変換
C++はC言語同様、型を明示的に指定して指定した型へ変換することももちろんできます。
C言語よりこの機能が細分化され、より安全になっています。(思わぬ型変換が発生しにくいという意味です。)
C++で使える明示的な型変換(キャスト)は以下の通りです。
| 書き方 | 説明 | デメリット |
|---|---|---|
| static_cast<型>(右辺値) | 最も安全なキャスト | ダウン・キャストは危険 |
| dynamic_cast<型>(右辺値) | 安全なダウン・キャスト | 遅い処理系がある |
| const_cast<型>(右辺値) | 面倒なconstを外す | 折角のconstが無効になる |
| reinterpret_cast<型>(ポインタか参照か整数型) | ポイント先の型を別の型へすげ替える | 危険 |
| (型)式 | Cスタイルのキャスト | 超危険 |
2-1.static_cast
スタティック・キャストと呼びます。名前の通りstaticに型を変換します。
この場合のstaticはコンパイル時に変換すると言う意味です。
例外が1つありますが、基本的に安全なキャストです。
例えば、1-2.の冒頭の例で「曖昧」にしないためにキャストすることがあります。
#include <iostream>
void foo(float x)
{
std::cout << "foo(float x) x=" << x << "\n";
}
void foo(double x)
{
std::cout << "foo(double x) x=" << x << "\n";
}
int main()
{
int x = 123;
foo(static_cast<double>(x));
}
また、通常のenum型やScoped Enum型でそのままでは代入できない時にキャストして代入します。
#include <iostream>
enum Foo
{
none, // 0
symbolA, // 1
symbolB // 2
};
enum class Bar
{
none, // 0
symbolA, // 1
symbolB // 2
};
int main()
{
Foo aFoo = none;
// aFoo = 1; // invalid conversion
aFoo = static_cast<Foo>(2);
std::cout << "aFoo=" << aFoo << "\n";
Bar aBar = Bar::none;
// aBar = 1; // cannot convert
aBar = static_cast<Bar>(2);
// std::cout << "aBar=" << aBar << "\n"; // no match
std::cout << "aBar=" << static_cast<int>(aBar) << "\n";
}
Wandboxで試してみる(コメント行を有効にしてみて下さい。)
2-2.static_castの危険な使い方
static_castは最も安全な明示的型変換ですが、先に書いたように例外が1つあります。ダウン・キャストです。
アップ・キャスト/ダウン・キャスト
アップ・キャストは派生クラスへのポインタを基底クラスへのポインタへ型変換することです。
ダウン・キャストは基底クラスへのポインタを派生クラスのポインタへ型変換することです。
第23回目で使ったサンプルで説明します。
#include <iostream>
class Base
{
public:
int mBaseVar;
void BaseFunc() { std::cout << "BaseFunc()\n"; }
Base() : mBaseVar(10) { }
};
class Derived : public Base
{
public:
int mDerivedVar;
Derived() : mDerivedVar(100) { }
void DerivedFunc()
{
std::cout << "mBaseVar+mDerivedVar= " << mBaseVar+mDerivedVar<< "\n";
}
};
int main()
{
// No Good!!
Base base0;
Base* base1=&base0;
Derived* derived0 = static_cast<Derived*>(base1);
derived0->DerivedFunc();
// Acceptable
Derived derived1;
Base* base2=&derived1;
Derived* derived2 = static_cast<Derived*>(base2);
derived2->DerivedFunc();
}
BaseとDerivedは第23回目のサンプルのままです。main()関数を修正し、static_castしてます。
2-2-1.ダメな使い方
上記コードで”No Good!!”とした部分は、Baseクラスのオブジェクトを生成し、そこへのポインタをDerivedクラスへのポインタへstatic_castしています。
これは不正メモリアクセスになるので、たいへん危険です。
Derivedクラスのメモリ・イメージは次のようになります。

しかし、Deriveクラスへのポインタの指す先はBaseクラスですので、DerivedクラスのmDerivedVarメンバ変数の領域は獲得されていません。そして、その後Derivedクラスのメンバ関数DerivedFunc()を呼び出し、この関数はmDerivedVarをアクセスしています。ここはメモリが割り当てられていないため、たまたまそのアドレスにあったメモリをアクセスしています。
ポインタの指す先のBaseクラスのオブジェクトをローカル変数として獲得しましたので、スタック上に確保されています。従って、mDerivedVarメンバ変数にあたるメモリもスタック上にあります。
もしそれが関数の戻り番地だった場合、derived0 ->mDerivedVarになにか書き込むとプログラムは「暴走」します。戻り番地なら暴走するので間違ったことがわかりますが、もし、他の計算結果が保持されていたら、いつの間にか結果が化けるのです。これは辛いです。
2-2-2.ダメではない使い方
後半のAcceptableとコメントした方は、Derivedクラスのオブジェクトを確保し、それを一度アップ・キャストしてFooクラスへのポインタでポイントしました。そして、それをDerivedクラスへのポインタへダウン・キャストしています。この場合、derived2の指す先は正しくDerivedクラスのオブジェクトですから不正メモリ・アクセスが発生する心配はありません。こちらの使い方であれば不具合にはなりません。
以上は、static_castでダウン・キャストしたポインタが指す先が正しいことをコンパイラはチェックしてくれないということを示しています。プログラマが自分の責任でそれを保証しないといけません。
それは結構たいへんですしバグの元ですので、どうしても必要な時以外はしないことをお勧めします。
2-3.dynamic_cast
static_castと異なり、dynamic_castは仮想関数のvtableポインタを使ってダウン・キャストします。
基底クラスへのポインタの指す先のオブジェクトの中にvtableポインタがあります。そして、そのvtableポインタは派生クラスのvtableを指していますから、変換先の派生クラスと同じかどうかチェックできます。
これにより、もし間違った型へ変換しようとしていた場合、dynamic_castはnullptrを返却します。
つまり、変換後のポインタをチェックすることで正しく変換できたことを確認できますので安全なのです。
サンプルです。2-2-1.の例とほぼ同じですが、2-2-1.は仮想関数を定義していませんのでvtableがありません。このサンプルではvtableを作るため、Baseクラスに仮想デストラクタを追加しています。
#include <iostream>
class Base
{
public:
int mBaseVar;
void BaseFunc() { std::cout << "BaseFunc()\n"; }
Base() : mBaseVar(10) { }
virtual ~Base() { }
};
class Derived : public Base
{
public:
int mDerivedVar;
Derived() : mDerivedVar(100) { }
void DerivedFunc()
{
std::cout << "mBaseVar+mDerivedVar= " << mBaseVar+mDerivedVar<< "\n";
}
};
int main()
{
// No Good!!
Base base0;
Base* base1=&base0;
Derived* derived0 = dynamic_cast<Derived*>(base1);
// derived0->DerivedFunc();
std::cout << "derived0=" << derived0 << "\n";
// Acceptable
Derived derived1;
Base* base2=&derived1;
Derived* derived2 = dynamic_cast<Derived*>(base2);
derived2->DerivedFunc();
}
Wandboxで試してみる
virtual ~Base() { }をコメントアウトしてみて下さい。ありがたいことにdynamic_castがエラーになります。
2-3-1.dynamic_castは遅いと聞くので確認(静的リンク)
C++erの間で有名なEffective C++ 第3版によると、動的リンク・ライブラリに対応するため、vtableポインタを直接比較するのではなくクラス名を比較して正当性確認を行う実装も良くあるそうです。
そこで、まずは静的リンクですが、Visual C++とgccで処理時間を測ってみました。
#include <iostream>
#include "fine_timer.h"
struct VeryLongLongNameClass_Base
{
virtual ~VeryLongLongNameClass_Base() { }
};
struct VeryLongLongNameClass_Derived0 : public VeryLongLongNameClass_Base
{
};
struct VeryLongLongNameClass_Derived1 : public VeryLongLongNameClass_Derived0
{
};
struct VeryLongLongNameClass_Derived2 : public VeryLongLongNameClass_Derived1
{
};
volatile int x=0;
struct VeryLongLongNameClass_Derived3 : public VeryLongLongNameClass_Derived2
{
void dummy()
{
++x;
}
};
int main()
{
VeryLongLongNameClass_Derived3 aDerived;
VeryLongLongNameClass_Derived3* aDerivedPtr;
VeryLongLongNameClass_Base* aBasePtr;
aBasePtr = &aDerived;
{
FineTimer ft;
for (size_t i=0; i < 100000000; ++i)
{
aDerivedPtr = static_cast<VeryLongLongNameClass_Derived3*>(aBasePtr);
aDerivedPtr->dummy();
}
std::cout << "static_cast = " << ft.mSec() << "\n";
}
{
FineTimer ft;
for (size_t i=0; i < 100000000; ++i)
{
aDerivedPtr = dynamic_cast<VeryLongLongNameClass_Derived3*>(aBasePtr);
aDerivedPtr->dummy();
}
std::cout << "dynamic_cast = " << ft.mSec() << "\n";
}
}
dummy()関数は最適化されてキャスト処理が消えてしまわないようにするためです。
このような最適化を阻む処理がないと実行時間は0になってしまいます。
Visual C++ 2015の実行結果(mSec)
| cast方法 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 |
|---|---|---|---|---|---|
| static_cast | 197 | 180 | 200 | 200 | 200 |
| dynamic_cast | 6,679 | 6,716 | 6,691 | 6,673 | 6,680 |
Effective C++の記述に従って遅くなるよう「長いクラス名」を使い深い継承をしたせいもあると思いますが、びっくりの遅さです。
興味のある方は、短いクラス名にしたり浅い継承にしたりして確認されてみて下さい。
gcc 5.4.0の実行結果(mSec)
| cast方法 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 |
|---|---|---|---|---|---|
| static_cast | 205 | 207 | 204 | 208 | 208 |
| dynamic_cast | 208 | 205 | 200 | 202 | 205 |
大差ないですね。Effective C++の記述はてっきりgccのことと思っていましたが、少なくともstaticリンク時は遅くならないようです。
2-3-2.dynamic_castは遅いと聞くので確認(動的リンク)
気になったので動的リンクでも計測してみました。
Visaul C++は動的リンク・ライブラリを呼び出すために呪文(__declspec(dllimport)/__declspec(dllexport))が必要です。デフォルトでは動的リンク・ライブラリからシンボルをエクスポートしないため、どのシンボルをエクスポートするのか指定する必要があるのです。
gccは呪文はいりません。デフォルトで全てのシンボルをエクスポートするからです。
#ifndef CAST_H
#define CAST_H
#if !defined(EXPORTING)
#if defined(_MSC_VER)
#define DLL __declspec(dllimport)
#else
#define DLL
#endif
#else
#if defined(_MSC_VER)
#define DLL __declspec(dllexport)
#else
#define DLL
#endif
#endif
struct DLL VeryLongLongNameClass_Base
{
virtual ~VeryLongLongNameClass_Base() { }
};
struct DLL VeryLongLongNameClass_Derived0 : public VeryLongLongNameClass_Base
{
};
struct DLL VeryLongLongNameClass_Derived1 : public VeryLongLongNameClass_Derived0
{
};
struct DLL VeryLongLongNameClass_Derived2 : public VeryLongLongNameClass_Derived1
{
};
DLL extern volatile int x;
struct DLL VeryLongLongNameClass_Derived3 : public VeryLongLongNameClass_Derived2
{
void dummy()
{
++x;
}
};
DLL VeryLongLongNameClass_Base* getDerived();
#endif // CAST_H
#define EXPORTING
#include "cast.h"
DLL extern volatile int x=0;
DLL VeryLongLongNameClass_Base* getDerived()
{
static VeryLongLongNameClass_Derived3 derived;
return &derived;
}
#include <iostream>
#include "fine_timer.h"
#include "cast.h"
int main()
{
VeryLongLongNameClass_Derived3* aDerivedPtr;
VeryLongLongNameClass_Base* aBasePtr;
aBasePtr = getDerived();
{
FineTimer ft;
for (size_t i=0; i < 100000000; ++i)
{
aDerivedPtr = static_cast<VeryLongLongNameClass_Derived3*>(aBasePtr);
aDerivedPtr->dummy();
}
std::cout << "static_cast = " << ft.mSec() << "\n";
}
{
FineTimer ft;
for (size_t i=0; i < 100000000; ++i)
{
aDerivedPtr = dynamic_cast<VeryLongLongNameClass_Derived3*>(aBasePtr);
aDerivedPtr->dummy();
}
std::cout << "dynamic_cast = " << ft.mSec() << "\n";
}
}
fine_time.hは上記と同じなので省略。
そして、CMakeを使えばお手軽です。
add_library()でライブラリを生成することを指示しています。この中のSHAREDで動的リンク・ライブラリを指定しています。
target_link_libraries()はcast(呼び出し側)にdll(ライブラリ)をリンクするよう指示してます。
project(cast)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
endif()
add_executable(cast cast.cpp cast.h)
add_library(dll SHARED dll.cpp cast.h)
target_link_libraries(cast dll)
Visual C++ 2015の実行結果(mSec)
| cast方法 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 |
|---|---|---|---|---|---|
| static_cast | 168 | 172 | 169 | 168 | 168 |
| dynamic_cast | 11,009 | 11,018 | 11,033 | 11,041 | 11,034 |
static_castが静的リンクの時より速いのはちょっと不思議ですが、大差はないので気にしないで良いと思います。
dynamic_castは更に遅くなってしまいました。困ったものです。
gcc 5.4.0の実行結果(mSec)
| cast方法 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 |
|---|---|---|---|---|---|
| static_cast | 252 | 254 | 254 | 256 | 251 |
| dynamic_cast | 1271 | 1262 | 1249 | 1260 | 1278 |
static_castもちょっと遅くなりましたが、dynamic_castは6倍くらい遅くなりました。
やはりdynamic_castをタイムクリティカルな場面で使う場合は注意が必要そうです。
動的リンク・ライブラリ
これらについて以前Qiitaへ投稿しました。興味がある方はそちらもご覧下さい。
C++形式の動的リンク・ライブラリの書き方(msvc編)
C++形式の共有ライブラリの書き方(gcc編)
2-4.const_cast
第32回目で解説したconst修飾を外すキャストです。
例えば、次のような悪用もできます。
#include <iostream>
void foo(int const& x)
{
int& y = const_cast<int&>(x);
y = 567;
}
int main()
{
int x = 123;
foo(x);
std::cout << x << "\n";
}
このような悪用をして痛い目に会うのは自分ですから、このような使い方は論外です。
しかし、constを外したいケースはあります。
例えば、クラスのメンバをファイルへ保存/回復するような場合、保存と回復の処理自体は本質的に同じものになる場合があります。(単にメンバ変数を並べれば良い。)
このような時でも、APIは出力用はconst型と入力用は非const側の2つを用意して使う人のバグを防ぐようにするべきです。しかし、内部処理でconstを維持したままですと、上記のように本質的に同じ処理でよいのにconst版と非const版の2つをかかないといけません。
前回でてきたoperator[]のように1行で済む場合はまだ許せますが、それなりに複雑な処理が必要だった場合に、ほぼ同じものでconstの有無だけが異なる大きめの関数を2つ書くのはDRY原則上避けるべきです。
このような時は、間違って対象変数へ書き込まないことを慎重に確認しつつ、const_castでconstを外し、2つの関数を1つにまとめるのも「有り」と思います。
Wandboxにサンプルを置いてます
2つ書きたくない処理はprocess_impl()です。これを2つ書きたくない気持ちが伝わるよう、ちょっと長くなるようにしたのでサンプルが少し長くなってしまいました。
process()がAPIです。こちらはやはりconst版と非const版の両方を用意することで、間違って入力ストリームへ出力しようとしたり、出力ストリームから入力しようとしたりした時、できるだけコンパイル・エラーにしたいものです。
2-5.reinterpret_cast
これは主にポインタや参照の型変換を行います。参照とポインタの間の変換はできませんが、ポインタ同士、参照同士であれば、ポイント先/参照先の型がなんであれ指定通り変換します。更にポインタとポインタを記録できる大きさ整数との間の変換も行います。そして、その値(アドレス)は一切変更しません。
簡単なサンプルです。
#include <iostream>
int main()
{
int a=123456789;
uintptr_t b=reinterpret_cast<uintptr_t>(&a);
double* c=reinterpret_cast<double*>(b);
int* d=reinterpret_cast<int*>(c);
std::cout << *d;
}
- まず、int型のaを確保し123456789を設定しています。
- そのaのアドレスをuintptr_t型変数bへ確保しています。(uintptr_tはポインタを記録できる大きさの整数値型です。C++11で規定されました。)
- そして、無茶なことにそれをdouble型を指すポインタへ変換しました。bに入っているアドレスはint型変数aのアドレスです。一般にdouble型はint型より大きいため、cが指す領域はdouble型より小さい領域しか確保されていません。もしもアクセスすると不正メモリ・アクセスになります。アクセス違反で落ちればまだしも、そのまま動き続けた時が恐怖です。
- 更にdouble型へのポインタcをint型へのポインタdへ変換しました。これは元々int型を指していたポインタを戻したものですから、安心してアクセスできます。
- ポインタdの指す先を表示すると、1.で設定した値と同じ値が表示されます。
このような危険な変換を許す型変換がreinterpret_castです。
C言語は型に関するサポートが非常に弱いため、reinterpret_castよりも更に傍若無人なCスタイル・キャストを用いないとやりたいことをやる術がありませんでした。しかし、C++は型のサポートがかなり手厚く、ほとんど全てのケースで型情報を維持したままプログラムすることができます。
型情報を維持しておけば明らかに間違った代入を行った瞬間コンパイラがエラーや警告を出して、「何か間違ってませんか?」と聞いてきますので事前にバグをチェックできる場合も多くデバッグが捗ります。
ですので、(C++のメモリ・オペレーションと型操作についてかなり習熟するまでは)reinterpret_castを使わないことをお勧めします。
2-6.C言語スタイルのキャスト
(型)で型変換するキャストのことです。問答無用で変換します。C++のように「何かお間違いでは?」とチェックする機能はありません。プログラマが間違ったら間違った通りに動作しますから、デバッグで非常に苦労することになりがちです。
そして、reinterpret_cast以上に必要になることはありません。私はまともにC++で書き始めてから、C言語スタイルのキャストを必要としたことはありません。恐らくこれからも無いのではないかと思います。
更に、C++スタイルのキャストと異なり、エディタ等で検索できません。「Cスタイル・キャストが怪しいかも」と思ってもリストする術がないのでチェックはたいへんです。
このように、C言語スタイルのキャストを使うということはC++のバグ・チェック機能を「問答無用」で回避するものです。Cスタイル・キャストは使わないことを非常に強くお勧めします。
2-7.アップ・キャスト/ダウン・キャスト補足
多重継承している時のアップ・キャストとダウン・キャストは結構頭痛いです。
struct Base0
{
int mInt;
Base0() : mInt(12345) { }
virtual ~Base0() { }
};
struct Base1
{
float mFloat;
Base1() : mFloat(678.9) { }
virtual ~Base1() { }
};
struct Derived : public Base0, public Base1
{
short mShort;
Derived() : Base0(), Base1(), mShort(123) { }
};
のようにBase0とBase1を多重継承しているDeriveのメモリ・イメージは次のようになります。
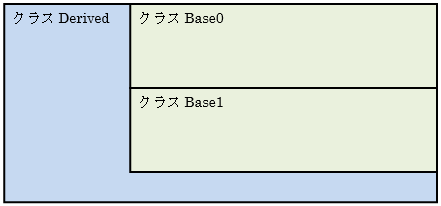
見ても分かるようにBase0とBase1は異なるメモリが割り当てられますので、それぞれの先頭アドレスは異なります。多くの処理系で先頭の基底クラスと派生クラスの先頭アドレスは同じですが、2番目以降の基底クラスの先頭アドレスは後ろへズレます。
static_castとdynamic_castはそのズレに追従し、ポインタは適切なオブジェクトを指します。
しかし、reinterpret_castは追従しません。DerivedへのポインタをBase1へのポインタへreinterpret_castしても、アドレスはDerivedへのポインタのままですから、ポインタの指す先にはBase0があり不適切な変換となります。
その様子が分かるサンプルを作ってみました。
int main()
{
Derived derived;
Base0* base0;
Base1* base1;
Derived* derived0;
Derived* derived1;
// static_cast
std::cout << "--- static_cast ---\n";
base0 = &derived;
base1 = &derived;
std::cout << " base0=" << base0 << " base1=" << base1 << "\n";
derived0 = static_cast<Derived*>(base0);
derived1 = static_cast<Derived*>(base1);
std::cout << " derived0=" << derived0 << " derived1=" << derived1 << "\n";
std::cout << "base0->mInt=" << base0->mInt
<< " base1->mFloat=" << base1->mFloat << "\n";
// dynamic_cast
std::cout << "--- dynamic_cast ---\n";
base0 = &derived;
base1 = &derived;
derived0 = dynamic_cast<Derived*>(base0);
derived1 = dynamic_cast<Derived*>(base1);
std::cout << " base0=" << base0 << " base1=" << base1 << "\n";
std::cout << " derived0=" << derived0 << " derived1=" << derived1 << "\n";
std::cout << "base0->mInt=" << base0->mInt
<< " base1->mFloat=" << base1->mFloat << "\n";
// dynamic_cast
std::cout << "--- reinterpret_cast ---\n";
base0 = reinterpret_cast<Base0*>(&derived);
base1 = reinterpret_cast<Base1*>(&derived);
std::cout << " base0=" << base0 << " base1=" << base1 << "\n";
derived0 = reinterpret_cast<Derived*>(base0);
derived1 = reinterpret_cast<Derived*>(base1);
std::cout << " derived0=" << derived0 << " derived1=" << derived1 << "\n";
std::cout << "base0->mInt=" << base0->mInt
<< " base1->mFloat=" << base1->mFloat << "\n";
}
--- static_cast ---
base0=0x7ffd8c1ba890 base1=0x7ffd8c1ba8a0
derived0=0x7ffd8c1ba890 derived1=0x7ffd8c1ba890
base0->mInt=12345 base1->mFloat=678.9
--- dynamic_cast ---
base0=0x7ffd8c1ba890 base1=0x7ffd8c1ba8a0
derived0=0x7ffd8c1ba890 derived1=0x7ffd8c1ba890
base0->mInt=12345 base1->mFloat=678.9
--- reinterpret_cast ---
base0=0x7ffd8c1ba890 base1=0x7ffd8c1ba890
derived0=0x7ffd8c1ba890 derived1=0x7ffd8c1ba890
base0->mInt=12345 base1->mFloat=1.7299e-41
最後のreinterpret_cast で変換した時、base1はbase0を指しているため、mFloatは実はmIntの位置を指しています。int型とfloat型ではメモリ内の表現方法が異なるのでint型の12345はfloat型ではこのような変な値となってしまいます。
3.まとめ
ちょっと駆け足でしたが、C++の型変換について解説しました。
以下の機能は多くの人が使う機会があると思います。
- 暗黙の型変換は便利ですが時に思わぬ変換をするのでそれを回避するのにexplicitが使えること
- static_castは安全ですがダウン・キャストに使うと危険なこと
- dynamic_castならそのダウン・キャストを安全に行えること
- const_castでconstを外せること
また、reinterpret_castの危険性を解説しました。多重継承時のアップ・キャスト/ダウン・キャストはアドレスの変更を伴うのでreinterpret_castは使わないことも重要です。reinterpret_castはかなり深くC++を理解するまで使わないようにしましょう。
そして、C言語スタイルのキャストは問答無用すぎますし、必要性は事実上ありません。使うのをやめることを強くお勧めします。
さて、当講座もそろそろ大詰めです。
コンパイラが自動的に生成する関数が幾つかあるのですが、それらを特殊メンバ関数と呼びます。
これらがあるので構造体を代入しただけでコピーできてしまいます。来週はこれらの特殊メンバ関数について解説します。お楽しみに。

Pingback: 型キャストとgoto fail | | がぶろぐ