
こんにちは。
今回はコンピュータの基本的な仕組みについて簡単に説明したいと思います。
C++で高速なプログラムを書くために是非理解しておきたい重要なことなのです。
コンピュータの重要な要素は、CPU、メモリ、ハードディスク、入出力装置です。
入力装置(例えばキーボード)で命令を与え、CPU/メモリ/ハードディスクでその命令に従って計算等の情報処理を行い、出力装置(例えばディスプレイ)へ結果を表示します。
CPUは人の頭脳、メモリは机(デスクトップ)、ハードディスクは本棚に良く例えられます。ついでに、入力装置を人の耳、出力装置を人の口に例えることができます。
この例えにおいて、人(コンピュータ)は耳で命令を聞き取り、本棚から必要な資料(ファイル)を取り出して机に広げて命令を実行します。そして、結果を口頭で返します。現実の人間は耳で聞いて口で答えますが、コンピュータはキーポードで命令を受け取り、ディスプレイに結果を表示します。1対1のチャットやLineで会話しているイメージに近いです。
さて、人に例えてみましたが現実のコンピュータは人ではないので、若干古いですが実物の写真を示します。

これが情報処理を行う中心となる部品です。
この情報処理能力がコンピュータ全体の処理性能に最も大きく影響します。
そして、写真のように全体が銀色ですが、これは半導体(シリコン)の色が見えています。

非常に高速に読み書きできますので、机のような作業用のスペースとして使います。
ここに情報処理を行うデータやプログラムを記録して、CPUでプログラムを実行しつつ、
データを処理します。
机は電源を切ることはできませんので作業中の状態を翌日に持ち越せますね。
しかし、メモリは電源を切ると書き込んだデータを失なってしまいます。
夜PCの電源を切る人は多いと思います。一度電源を切ると、元の状態を回復するにはそれなりの回復手順が必要になります。
PCの「スリープ」はメモリの電源を切らない仕組みです。なので回復手順が単純なため、短時間でスリープ前の状態に戻ります。
PCの休止状態(ハイバネーション)は、メモリの内容を一旦ハードディスクへ保存し、メモリの電源を切ります。回復時はハードディスクへ保存していた内容をメモリへ回復する必要があるので元の状態に戻るまでに少し時間がかかります。
写真上の黒い四角い部分がメモリ本体です。

メモリに比べると読み書きの速度はかなり落ちますが、大量に低価格でデータを記録でき、しかも、電源を切っても書き込んだデータは失われません。ですので、本棚のように大量の資料を保存するのに使われます。
しかし、ハードディスクに仕舞ったたままでは読み書き速度が遅いです。そこで、高速に情報処理するために通常はメモリへ持ってきて(ロードして)作業します。
Windowsやlinux等のOS本体もここに記録され、PCの電源を入れた時にメモリへ読み込まれます。
内部には磁性体のディスク(円盤)が入っていて高速で回転しています。その上を磁気ヘッドが左右に動いて必要なデータを読み書きします。壊れたHDDが手元にあったので分解してみました。

PCのスペック・シートを見ると分かりますが、最近のPCは4G(ギガ)バイトや8Gバイトなど、かなり巨大なメモリを内蔵していますね。
さて、1ビットは0か1のどちらかを記録できる情報の最小単位です。それが8つ集まって1バイトです。メモリの場合、1,024バイト(2の10乗)で1K(キロ)バイトと表現します。1Kバイトの1,024倍が1M(メガ)バイトです。更にその1,024倍が1G(ギガ)バイトです。気が遠くなりそうなほど、凄まじい情報量です。
数字で見る朝日新聞によると新聞1部の文字の量は約179,000字だそうです。
日本語1文字は2バイトで記録できますので358,000バイトですね。1,024で割ると約350Kバイトとなります。350キロ・バイトx1,024×3は概ね1Gバイトになります。
つまり、1Gバイトで新聞約3千部です。朝刊だけ取っている家庭にとって約8年半の新聞と同等の情報量です。最近のPCには、更にその4倍や8倍の情報量を記録できる量のメモリが搭載されています。
そして、このような情報を正しく読み書きするため、1バイト単位で「アドレス」と呼ばれる通し番号が割り振られており、メモリを読み書きする際「アドレス」で対象のメモリを指定します。例えば「アドレス=100番地のメモリを+1する」などです。
さて、4Gバイトは4×1,024×1,024×1,024バイトです。4は2ビット、1,024は10ビットですので、全部で32ビットあれば4Gバイトの各1バイト毎にアドレスを割り当てることができます。
ところで、32ビットってよく見かける数字ですね。32ビットのOSはアドレスを32ビットで表現するOSのことです。
4Gバイトを超えるメモリに対して、32ビットのアドレスではビット数が不足するため取り扱いが困難です。
そこで、最近は64ビットOSが多く用いられてます。これらのOSはアドレスを64ビットで表現しますので、4Gバイトの4ギガ倍のメモリを取り扱えます。これは16×10の18乗バイトを越えます。正に「天文学的な数字」ですね。
さて、C言語とC++にはポインタがあります。このポインタはこのアドレスを記録する変数の一種です。
32ビットOS用のプログラムではアドレスは32ビットですので、ポインタのサイズも32ビットです。
64ビットOS用のプログラムではアドレスは64ビットですので、ポインタのサイズも64ビットとなります。
このポインタにより、メモリ中の任意の1バイトを指定することが出来るわけです。
実際にはポインタはアドレスだけでなく、その指し示す先の変数の「型」も決めています。
int型のバイト数はコンパイラによって異なりますが、PCの場合は通常4バイトです。
int型へのポインタには、この連続する4バイトの先頭のアドレスが設定されます。
ポインタに設定されているアドレスで先頭の位置を示し、ポインタに結び付けられた「型」で先頭からのバイト数を示しています。
例えば、short型は2バイトのコンパイラが多いですが、そのようなコンパイラではshort型へのポインタにshort型先頭のアドレスが設定され、そのアドレスからの2バイトを指し示します。
例えば、下の図は32ビットOS用にコンパイルされたプログラムにおけるポインタの例を示しています。
int型のデータとそのint型データへのポインタを描いています。

まず、32ビットOS用のプログラムですので、アドレスは32ビット=4バイトです。
次に、int型の変数がアドレス0x01234564~0x01234567に割り当てられ、この変数には100が設定されています。
100は最下位のバイトが100で、その他の上位のバイトは全て0です。
PCの多くはインテルのCPUを内蔵しています。インテルCPUは数値をメモリに保存する時、下位のバイト→上位のバイトの順序で保存しますので、先頭アドレスに100が入り残りの3バイトには0が入っています。
最後に、そのint型の変数を指し示すint型へのポインタを描いてます。このポインタのサイズは32ビット=4バイトでint型の変数先頭のアドレスが設定されています。そして、int型へのポインタですので、このポインタはアドレス0x01234564~0x01234567を指し示しています。
駆け足で説明しましたが、雰囲気を掴んで頂けると幸いです。
分からない点がありましたら、コメント欄にて遠慮なくご質問下さい。
解説だけですと退屈ですし、自分でプログラムを触ってみないと意味が良く分からないと思います。
そこで、「アドレス」を表示するプログラムをサンプルとして作りました。極々簡単ですので色々触ってみて下さい。
C++ソースです。
内容は、以下の通りです。
5行目)int型の変数aDataを宣言し、100を設定します。
6行目)int型へのポインタを宣言し、aData先頭アドレスを設定します。
8行目)aDataの内容とaPointerの内容(アドレス)を表示します。
9行目)更にaPointerの先頭アドレスを表示しました。
basic_pointer.cpp
#include <iostream>
int main()
{
int aData=100;
int* aPointer=&aData;
std::cout << "aData=" << aData << " : aPointer=" << aPointer << "\n";
std::cout << "&aPointer=" << &aPointer << "\n";
return 0;
}
アドレス演算子&
このように変数の前に&を付けた場合、これは「アドレス演算子」となり、その変数の先頭アドレスを返します。
std::cout
std::coutは標準出力と呼ばれ、Windowsのコマンド・プロンプトやubuntuの端末に文字を表示する際に使います。
<<演算子で指定した定数や変数を表示します。<<演算子を下記のように連続して指定することで、左から順に出力されます。なお、std::coutは#includeすることで使えるようになります。
次に、CMakeのプロジェクト生成用のファイルです。
CMakeLists.txt
project(basic_pointer) add_executable(basic_pointer basic_pointer.cpp)
前回は特に目新しい内容は出てきていません。第2回、第3回の講座を参考にして下さい。
第2回、第3回と同様、Windowsもubuntuも同じコマンドでできます。
ソースとCMakeLists.txtをおいたフォルダでコマンド・プロンプト、もしくは、端末を起動し、下記コマンドを入力して下さい。
mkdir build cd build cmake .. cmake --build . --config Release
実行は少しコマンドが異なります。
Windowsは「cd Release; basic_pointer」です。
ubuntuは「./basic_pointer」です。
今回はデバッガを使ってみましょう。(ubuntuをお使いの方はこの節を飛ばして3-4へ進んで下さい。)
デバッグ・モードでビルドし、ブレーク・ポイントを設定して、デバッグ実行します。すると、設定したブレーク・ポイントで停止しますので、ステップ実行(1行毎に実行)しつつ、変数の値を観察してみましょう。
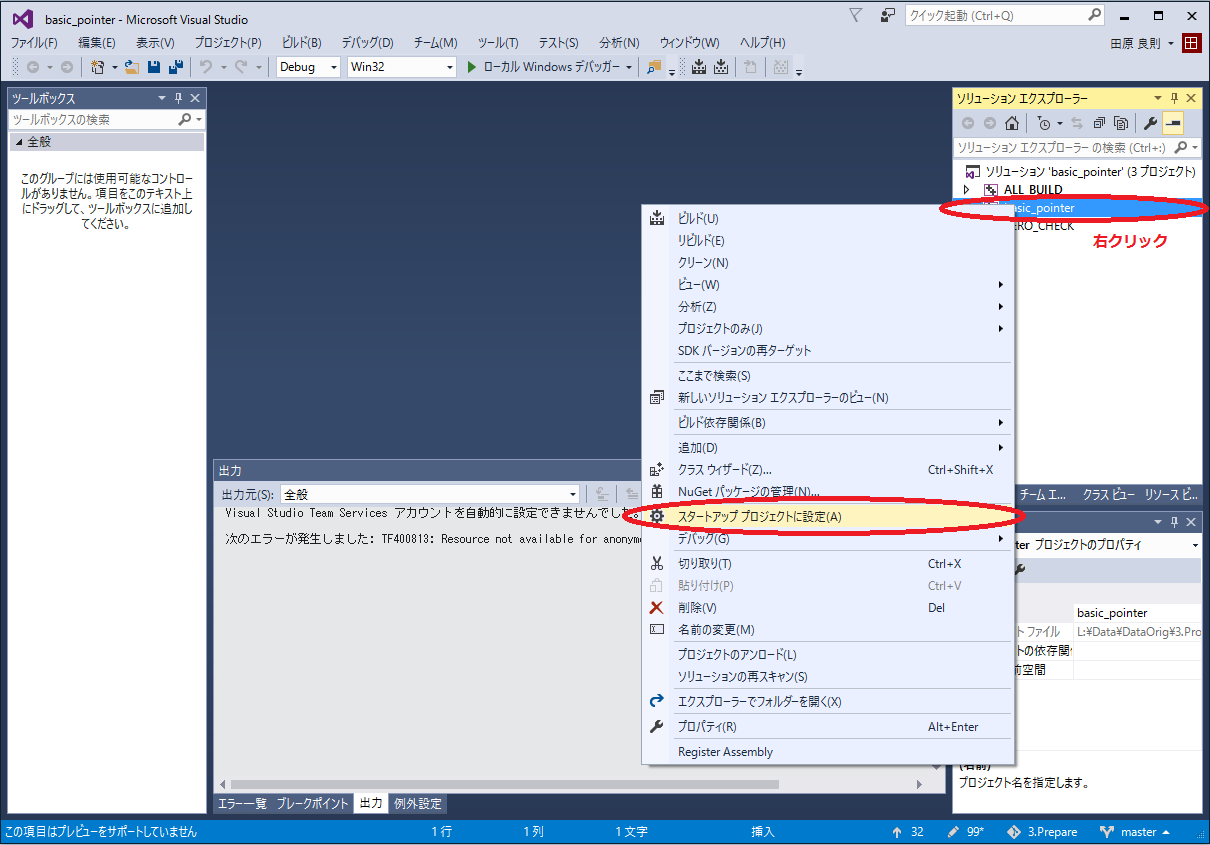
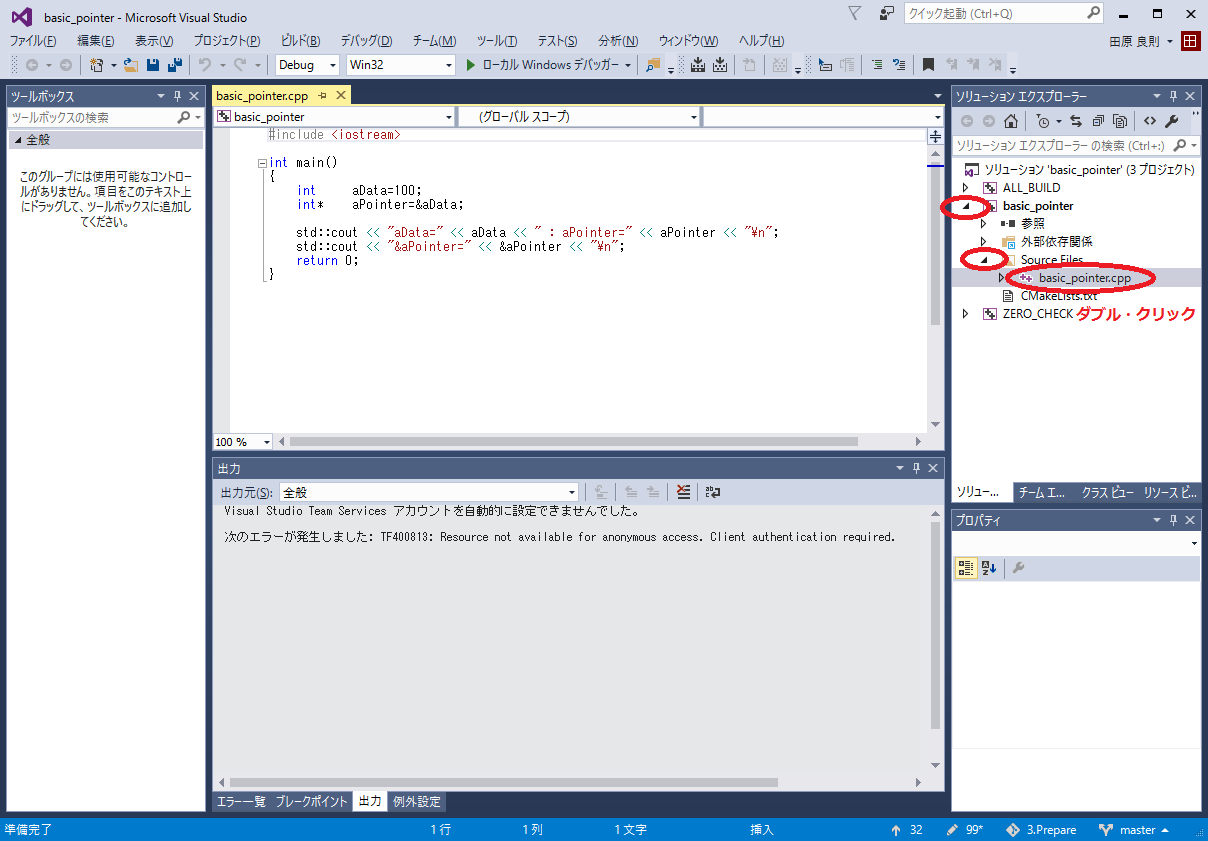
3-1で作成したビルド・プロジェクトの中にbasic_pointer.slnというファイルができていますので、これをダブルクリックして下さい。Visual Studioが起動します。
続けて、basic_pointerプロジェクトをスタートアップ・プロジェクトに設定し、ブレーク・ポイントをセットして、「ローカルWindowsデバッガー」ボタンを押すとデバッグ実行が開始されます。
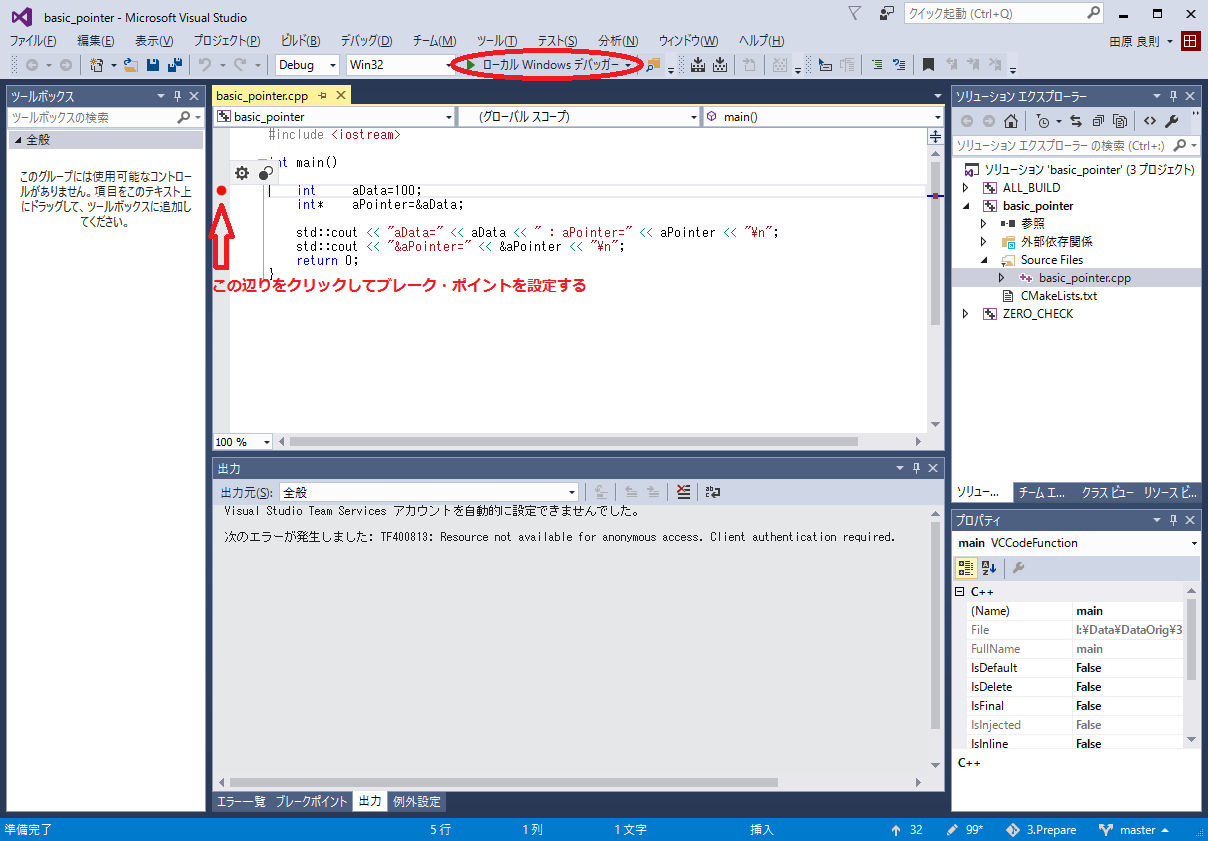
するとブレーク・ポイントで停止するので、下記画像のように操作してみて下さい。
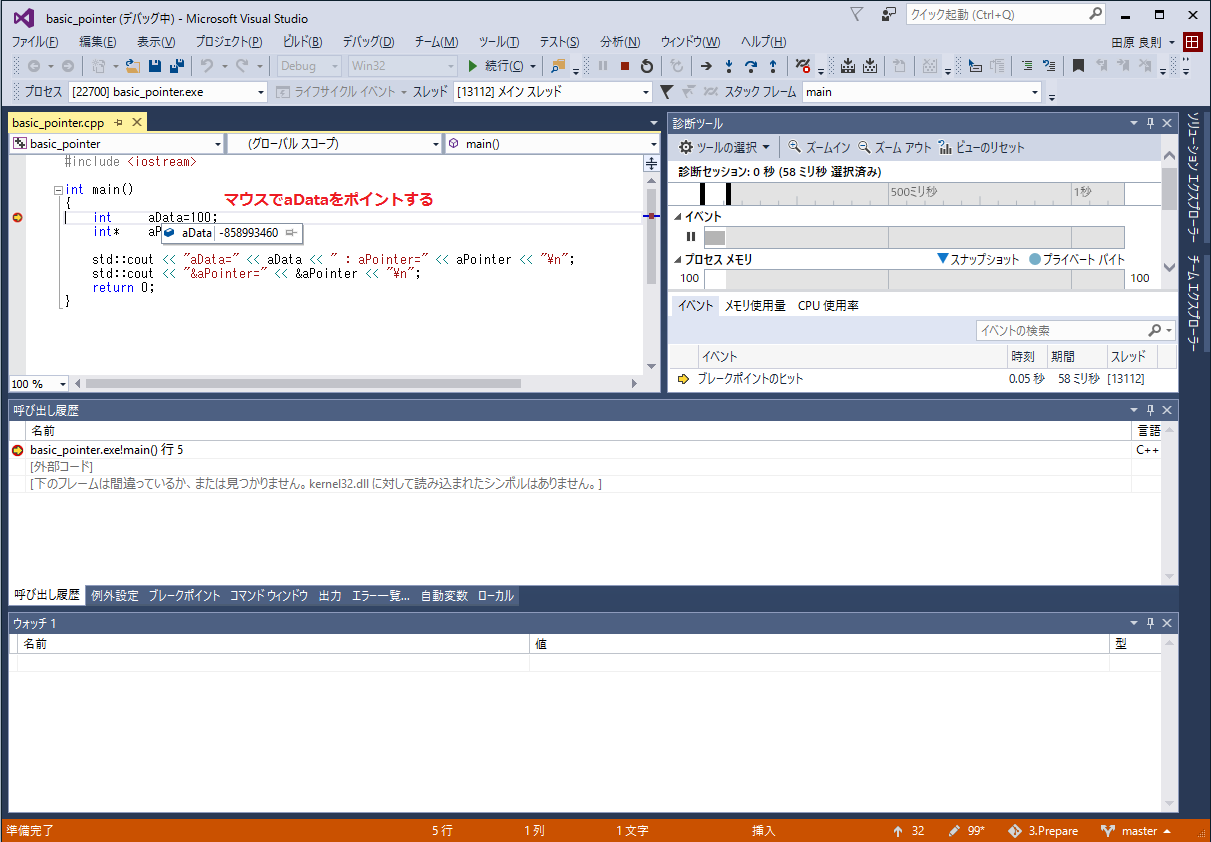
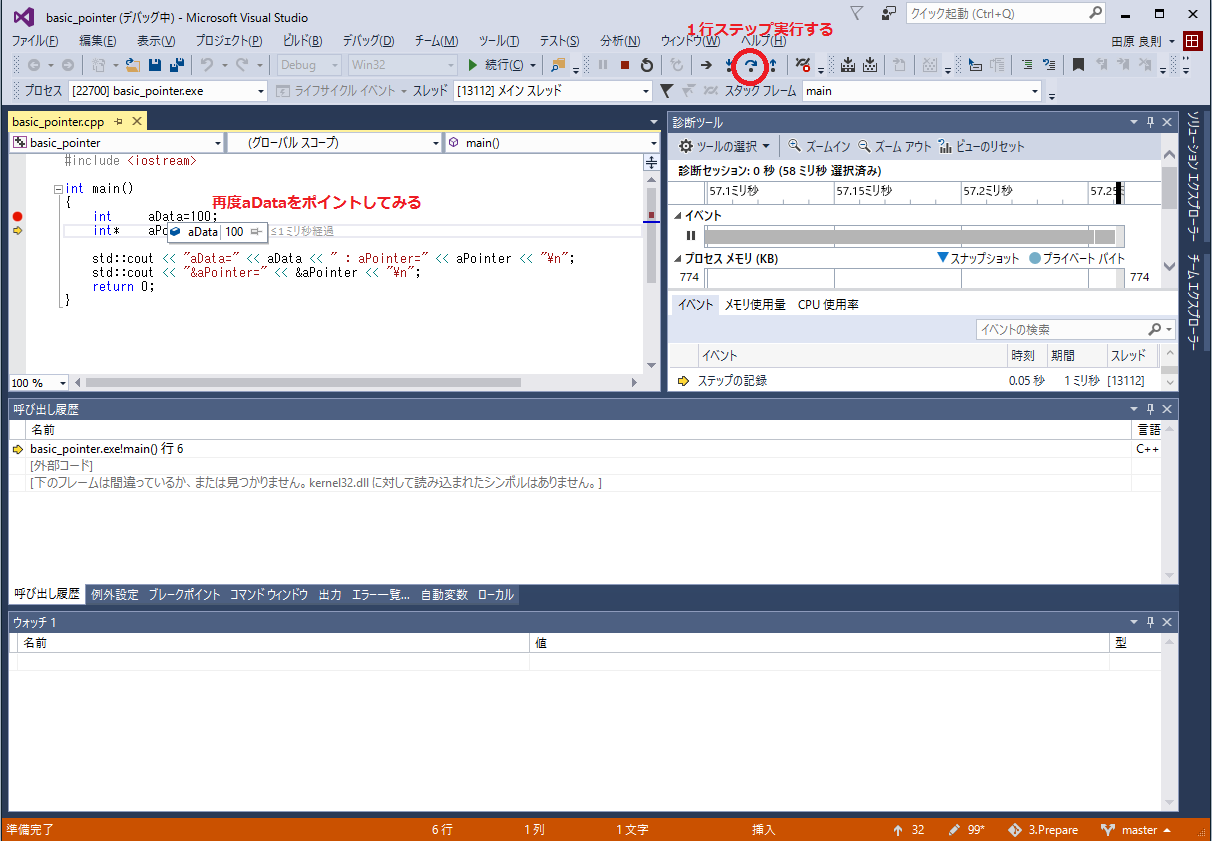
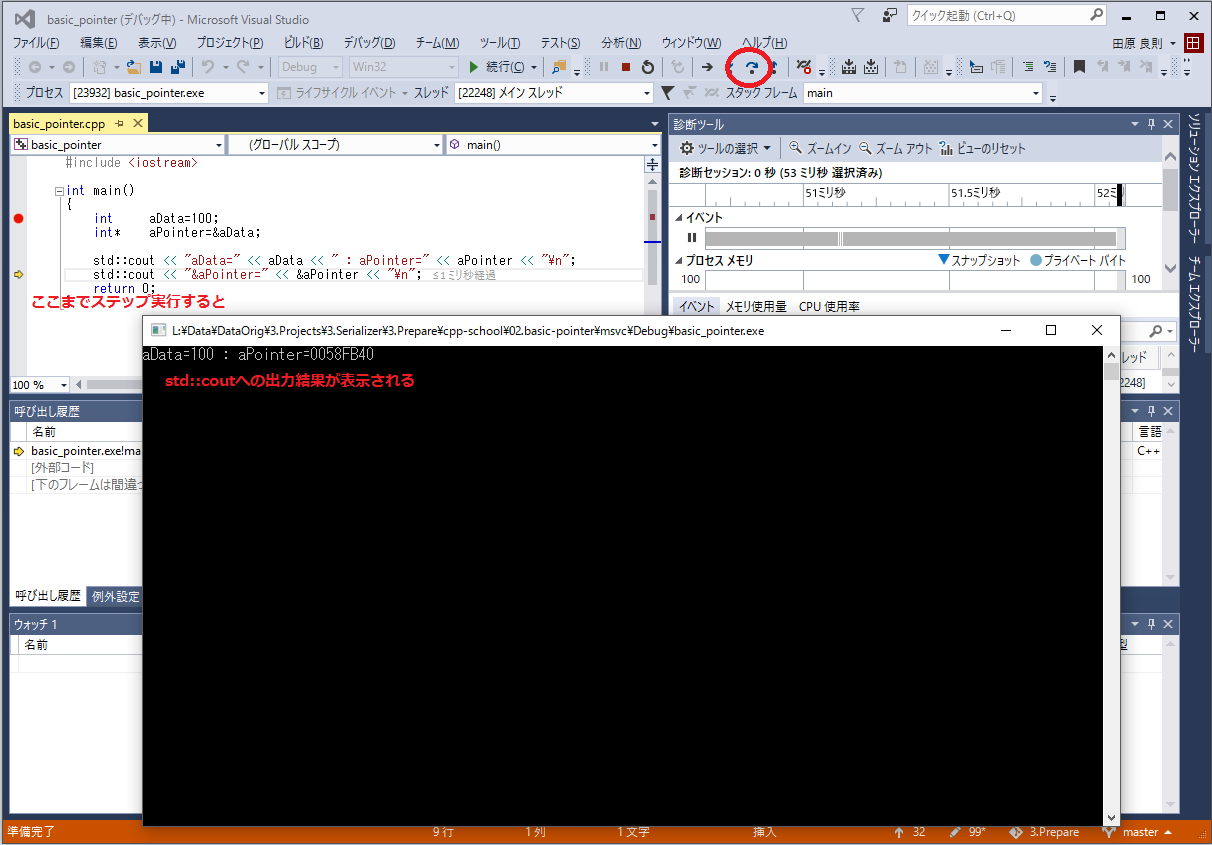
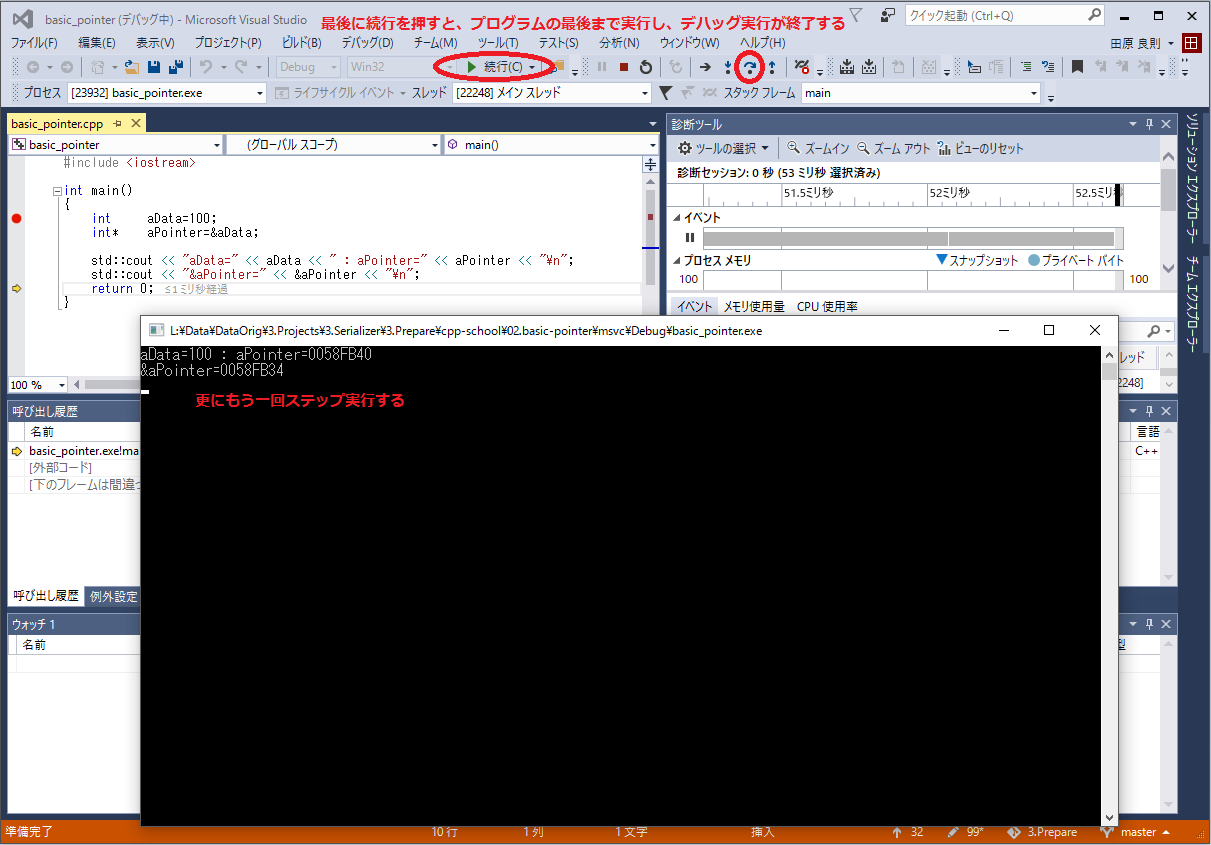
ブレーク・ポイントで止まったとき、ブレーク・ポイントのある行はまだ実行されていません。
つまり、最初に止まった時、int aData=100;の行は実行されていないため、aDataにはまだ100が設定されていません。そのため、aDataには「不定値」が入っています。
このように変数をポイントすることで内容を確認できます。今回は全ての変数の値を出力していますが、普通にプログラムを開発している最中はなかなか全ての変数の値を表示できませんので、このようにデバッガで観察すると楽にデバッグできます。
CMakeでビルド・プロジェクトを生成する時、64ビットOS用のビルドを指定しなかった場合、32ビットOS用にビルドされますので、32ビットOS用のプログラムとなっています。従って、ポインタのサイズは32ビット=4バイトです。
この状態を図で表すと下記となります。(なお、各変数に割り当てられるアドレスは実行の度に異なります。)

ここではCode::Blocksの使い方を説明します。
デバッグ・モードでビルドし、ブレーク・ポイントを設定して、デバッグ実行します。すると、設定したブレーク・ポイントで停止しますので、ステップ実行(1行毎に実行)しつつ、変数の値を観察してみましょう。
まず、Code::Blocksによるデバッグ用のビルド・プロジェクトを生成します。
第3回の場合とcmakeコマンドが異なりますので注意して下さい。「-DCMAKE_BUILD_TYPE=Debug」オプションでデバッグ・ビルドを指定しています。
$ mkdir codeblocks $ cd codeblocks $ cmake -G "CodeBlocks - Unix Makefiles" .. -DCMAKE_BUILD_TYPE=Debug
これにより、codeblocksフォルダにbasic_pointer.cbpファイルが生成されますので、これをダブル・クリックしてCode::Blocksを起動して下さい。
Build Targetをbasic_pointerにセットし、Sourcesを開いてbasic_pointer.cppをダブル・クリックして下さい。そして、ブレーク・ポイントを設定し、デバッグ実行を開始します。

するとブレーク・ポイントで停止するので、下記画像のように各変数をウォッチするよう設定して下さい。
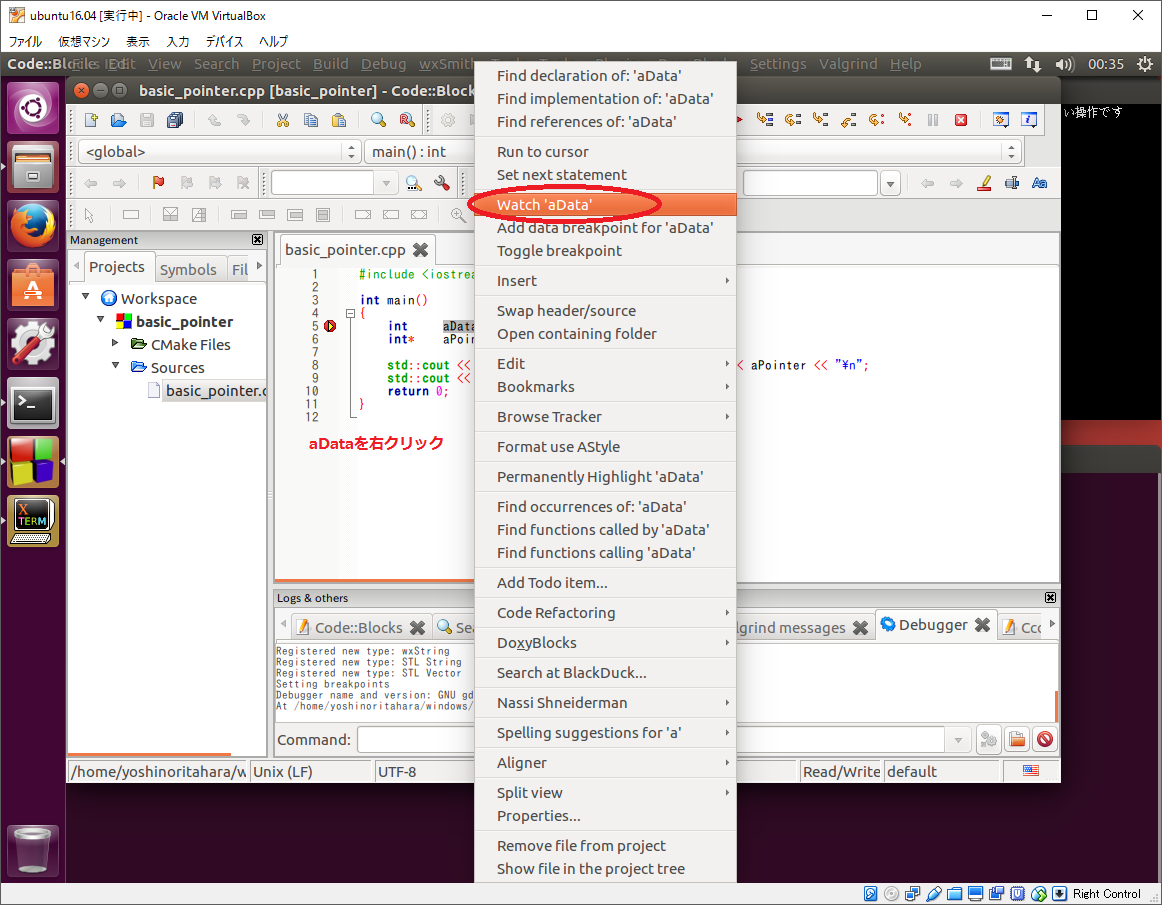
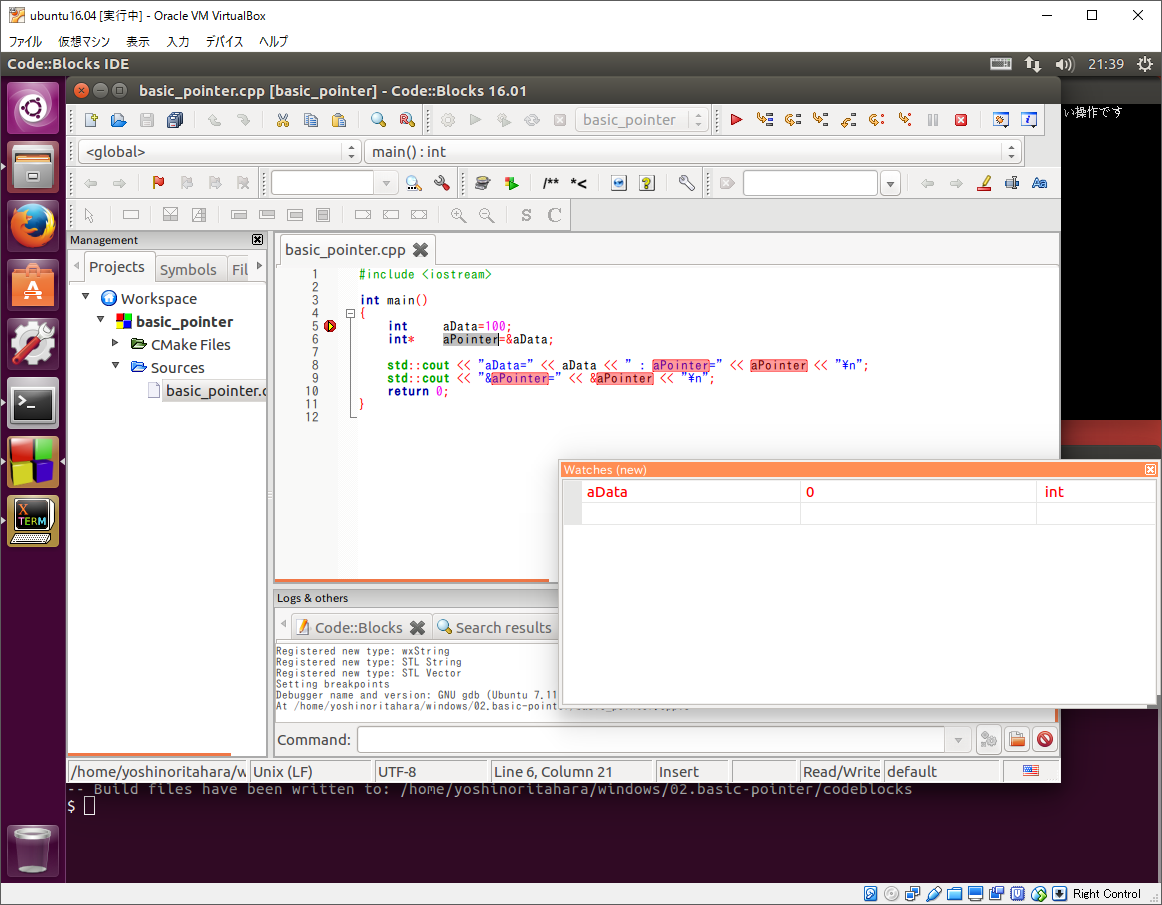
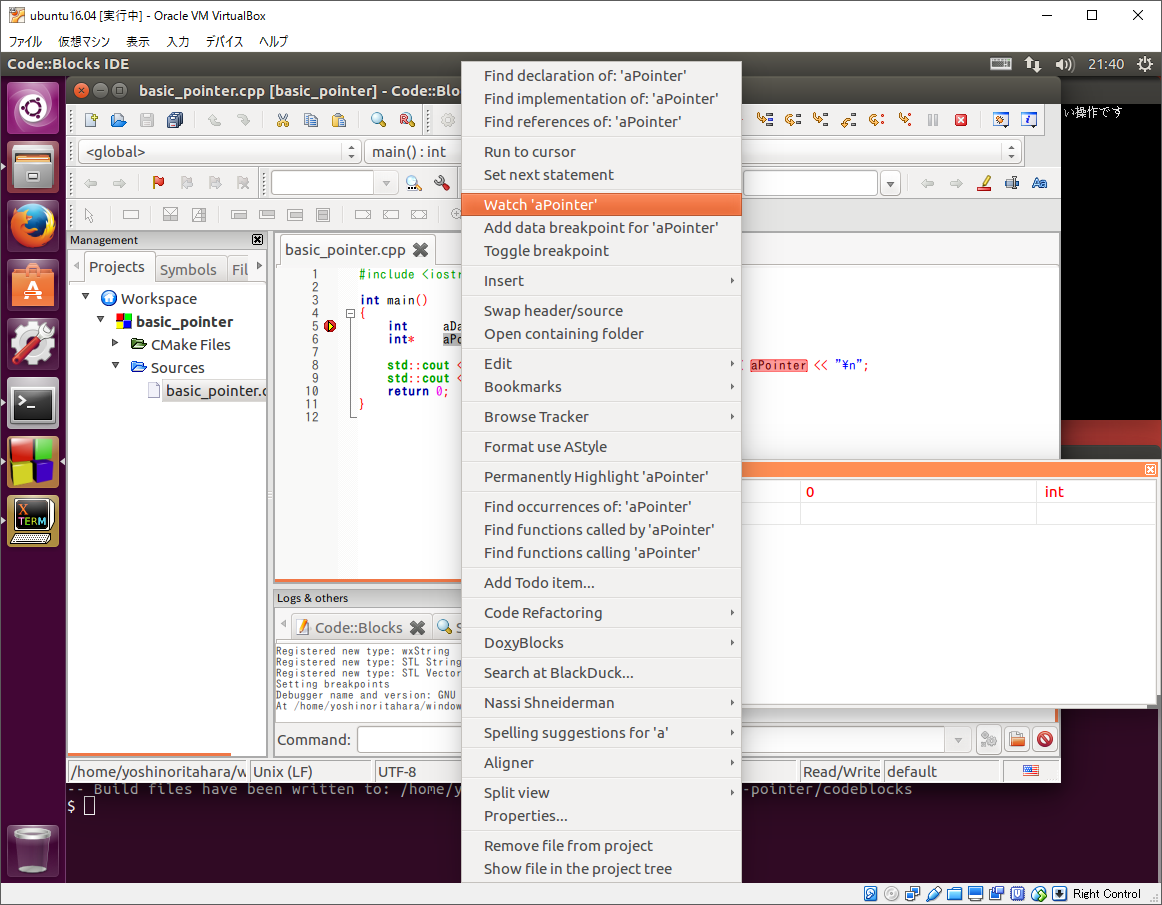
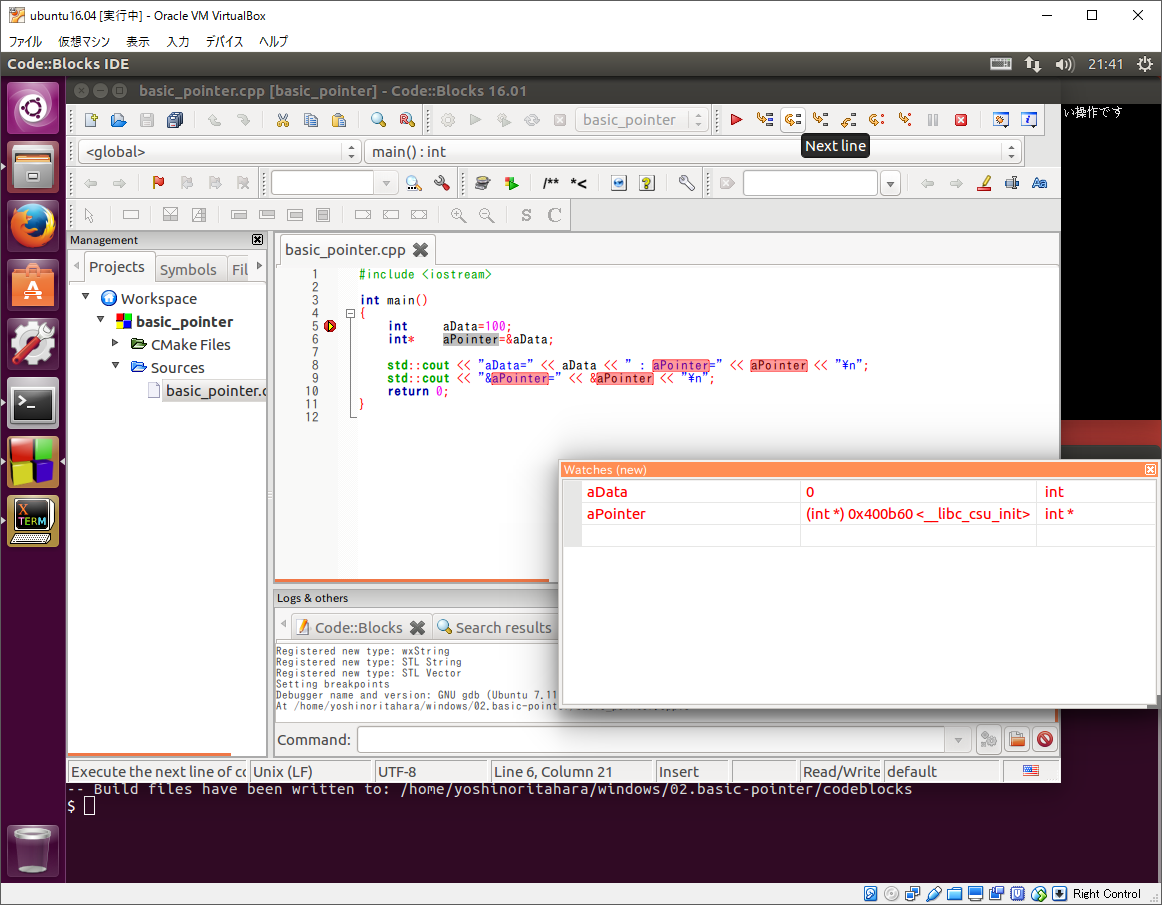
そして、そのままステップ実行して変数の変化とプログラムの出力をみて見ましょう。

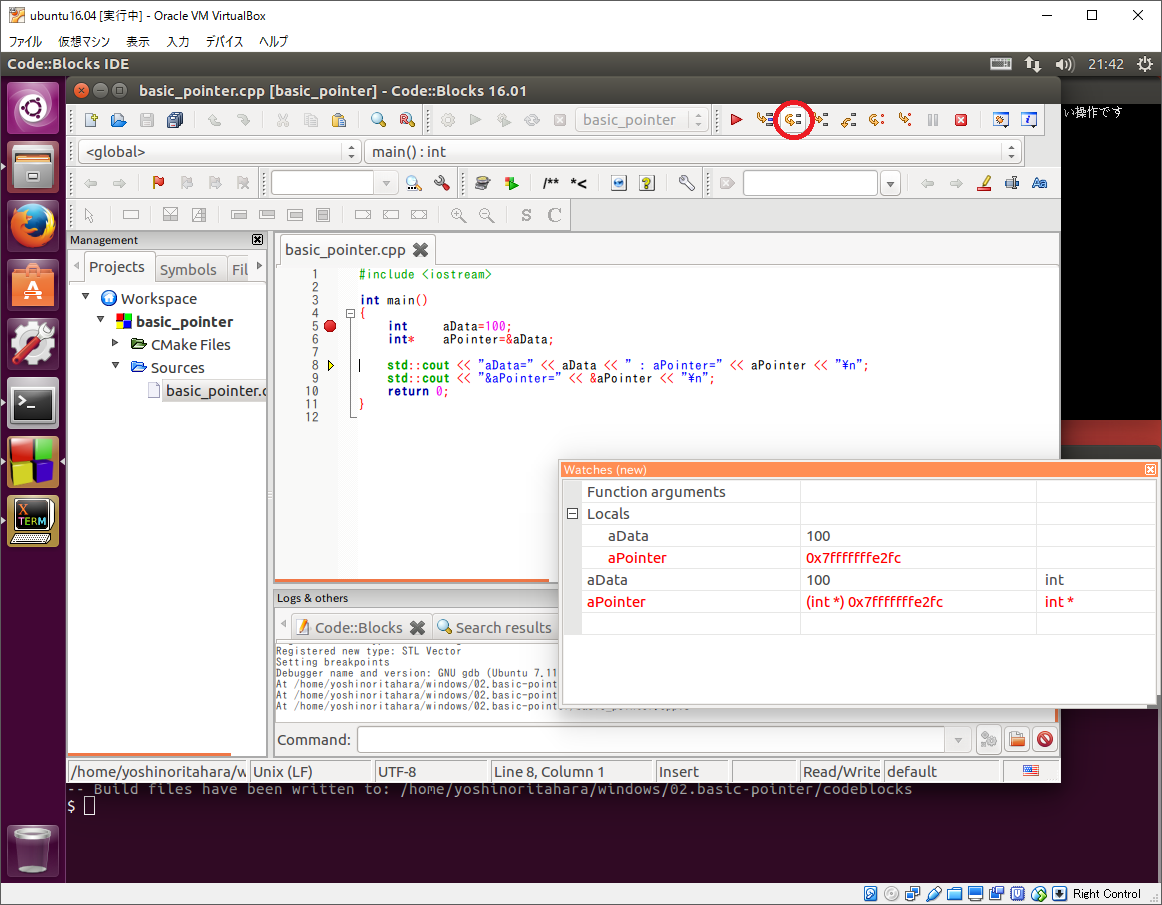
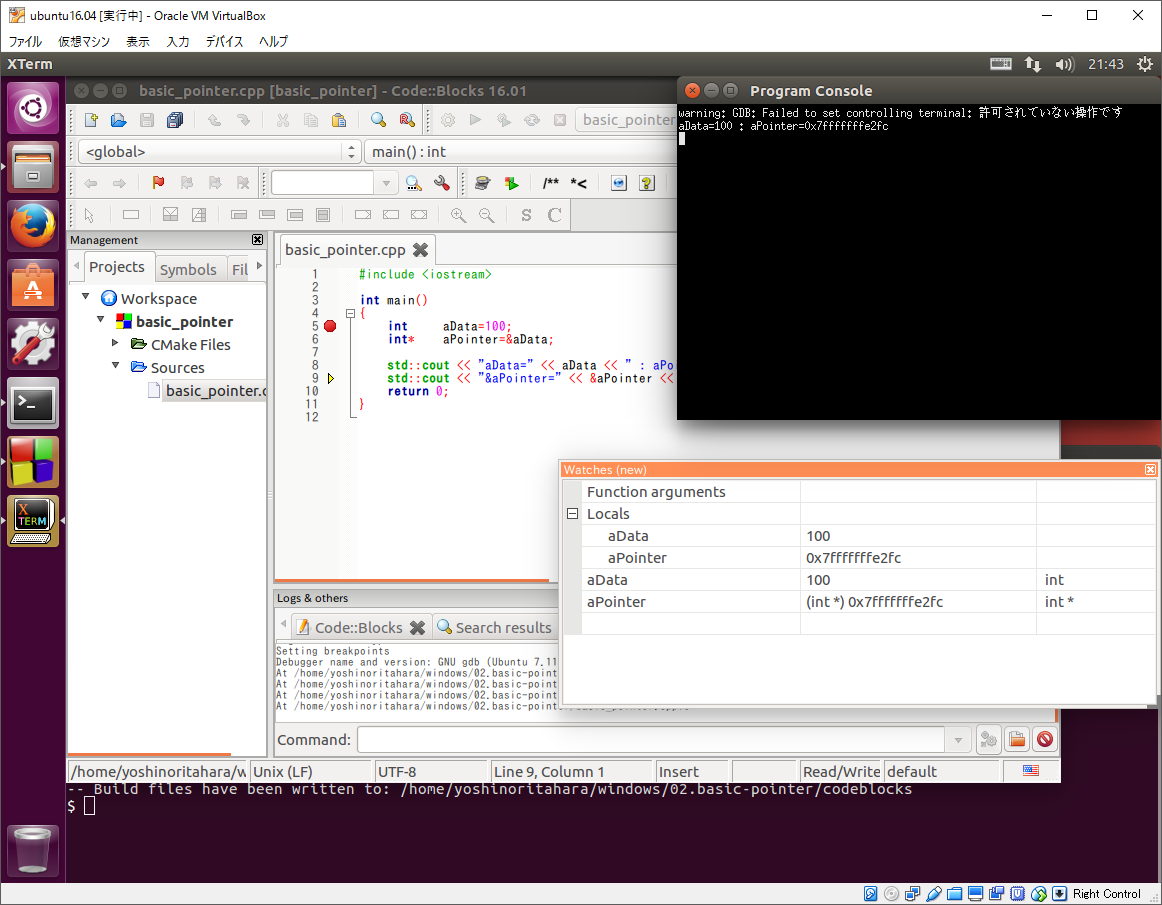
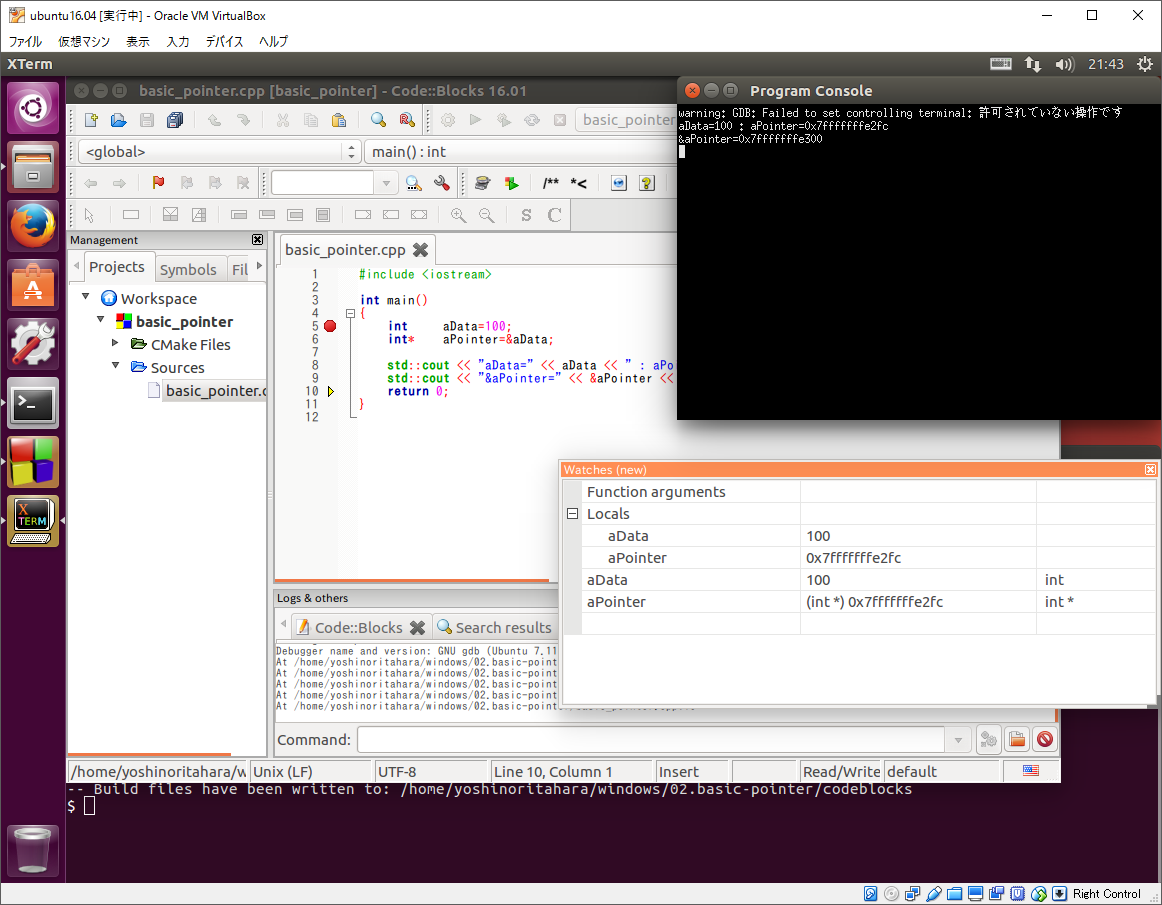
このように変数をウォッチすることで内容を確認できます。今回は全ての変数の値を出力していますが、普通にプログラムを開発している最中はなかなか全ての変数の値を表示できませんので、このようにデバッガで観察すると楽にデバッグできます。
このサンプルではubuntuは64ビット版を用いましたので、64ビットOS用にビルドされます。従って、ポインタのサイズは64ビット=8バイトです。
この状態を図で表すと下記となります。(なお、各変数に割り当てられるアドレスは通常は実行の度に異なります。)

今回、難しいと言われているポインタの解説を少しだけですが、いきなり行いました。
しかし、実は「メモリ」の概念を把握していればポインタは決して難しいものではありません。
メモリは単なるバイトの並びであり各バイトには通し番号(アドレス)が割り振られています。
そのメモリ上のどこかに変数が配置され、変数の先頭アドレスを指し示すのがポインタなのです。
難しいのはC言語やC++の文法と絡む時です。「構造体へのポインタの配列」はよく使うものの中で最も難しいものの1つと思います。それも文法を理解し今回のようなメモリ割り当て図と共に理解していけば、恐らくそれ程苦労しないと思いますので、今後の解説をお待ち下さい。
まだ、しっくりとは来ていないとは思いますが、頑張って下さい。
分からない時はどうぞご遠慮無く質問して下さい。
次回からC++の文法的な解説を初めます。最初はC言語レベルの簡単な部分から入ります。
お楽しみに。

先ほどもコメントした、
LinuxやC++、Qtを勉強中の者です。
コンピュータを人に例えるたとえ話がとてもわかりやすかったです!
そこで質問なのですが、
こちらにハードディスクは本棚という例えがありました。
OSはいわば本棚の中にある手順書のようなものなのでしょうか?
「OSとは」で検索すると、基本ソフトウェアと書かれていたりしますが、
ではOSのないマイコンは何なのだろう…
というような形でどんどん訳が分からなくなります。
お時間あるときにご教示いただけますと幸いです。
よろしくお願いいたします。