
こんにちは。田原です。
前回、スタックには関数が終了した時の戻り先が記録されることを説明しました。スタックには、「戻り先」以外にも関数の実引数と関数内で定義されるローカル変数も記録されます。
昔アセンブラしかやってなかった頃の私にとって本当に衝撃的でした。スタックに変数を記録するとか反則です。
今回は、そのようなスタックについて解説します。
関数を定義する時に引数のリストを書きますが、それは「仮引数」です。実際の値が入っていない仮に名前を付けたものと言う意味です。
そして、関数を呼び出す時に引数には実際の値を設定されます。この時の引数は実引数と呼ばれます。
一般的なプログラミング言語の引数の渡し方は大きく2つに分類されます。
- 値渡し
指定された式の計算結果をコピーして渡します。
右辺値を指定できます。
第6回目で解説したように右辺値は値です。計算結果の値をコピーして渡す、それだけですので考え方は単純です。 -
参照渡し(アドレス渡し)
指定されたアイテムのアドレスを渡します。
一般的には左辺値のみ指定します。
C言語は事実上値渡しだけでした。C++では値渡しに加えて参照渡しも使えるよう拡張されました。
参照渡しの物理的な仕組みは値渡しと同じですので、ここではまず基本の値渡しを解説します。
近々の内にポインタと参照の渡し方についても改めて解説する予定ですので、しばしお待ち下さい。
ポインタについて
C言語時代から、ポインタを関数へ渡すことができました。このポインタは「値渡し」なのか「参照渡し」なのか議論が分かれやすいのですが、C言語のポインタ渡しは値渡しと考えた方が学習が容易になります。ポインタ変数に設定されている値(アドレス)や、計算結果がポインタになる式(例えば、ptr+1など)の結果をコピーして渡していると考えて下さい。
C++の参照渡しについて
一般的には参照で渡せるものは左辺値(容器)であり変数です。
ただし、C++はすっとんだ先進的なアイデアで、値である右辺値を指定できる仕組みを導入し、より高速なプログラムを自然な記述で開発できるようになりました。右辺値参照と呼ばれる仕組みです。この概念は難しいので、当入門講座の最後の方で解説する予定です。
前回、関数からの「戻り先」がスタックに積まれることを説明しました。実引数もそのスタックに積んで渡されるように振る舞います。(*1)
さて、スタックで実引数を渡すと一言で言っても様々な渡し方があります。
どんな実引数を渡すのか決めるのは呼び出し側ですので実引数をスタックに積むのは呼び出し側です。積まれた実引数領域の解放は呼び出し側の場合と関数側の場合があります。また、「仮引数リストの順序で積むのか、逆順で積むのか」等の様々な方式があります。これらは呼出規約としてある程度標準化されていますが、原則として処理系(コンパイラ)毎に異なります。
(*1)実引数もスタックに積んで渡されるように振る舞います
標準規格でスタックで渡すようにと規定されているわけではありませんし、実際の渡し方も微妙に異なる場合があります。
CPUは内部にレジスタと呼ばれる幾つかの超高速なメモリを持っています。レジスタは数個~数10個程度しかないためアドレスは振られず、マシン後で直接レジスタ番号等を使ってアクセスされます。
例えば、引数リストの先頭から数個はそのようなレジスタを使って実引数が渡され、レジスタでは足りない分がスタックで渡されるような方法が使われる場合もあります。その場合でも、更に他の関数を呼ぶ時にレジスタの値はスタックに積まれ他の関数で破壊されないように退避/回復されますので、当講座ではCPU内部にあるレジスタも(明記した時を除き)スタック用メモリとして分類します。
C言語では、リストの逆順でスタックへ積んで関数を呼び出し、戻ってきてから呼び出し側で引数領域を解放する事が多いです。この仕組みはスマートですし、可変長引数(呼出毎に引数の数が異なる)を実現できます。
ちょっと横道にそれますが、可変長引数について実例を使って少し説明します。可変長引数を使っている有名な関数はprintf()関数です。例えば、x, y, zがdouble型変数で下記のような呼出を起こった場合を図示します。
printf("(x, y, z)=(%f, %f, %f)\n", x, y, z);
実引数を z → y → x の順序でスタックへ積んでから、戻り先を積みつつprintf関数を呼び出しますので、printf関数が呼ばれた直後は下図のようなメモリ・イメージとなります。
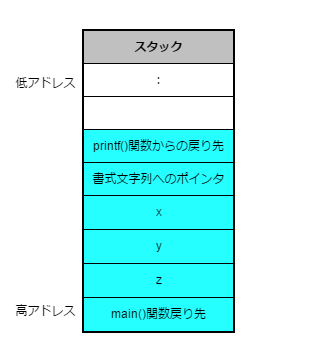
そして、printf()関数は最初の実引数である「書式指定文字列へのポインタ」を使って書式指定文字列をアクセスし、その中の%fが出て来る度に次の実引数をdouble型変数として処理します。つまり、printf()関数は書式指定文字列で実引数の型と数を定義しているのです。
C++でも関数の実引数の渡し方はC言語の仕組みを引き継いでますので、先に述べたのと同じ仕組みで引き渡されます。微妙に拡張されていますが、基本は同じです。
実際のアドレスを見てみましょう。
parameter.cpp
#include <iostream>
void foo(double x, double y, double z)
{
std::cout << "(x, y, z)=(" << x << ", " << y << ", " << z << ")\n";
std::cout << "&x=" << &x << "\n";
std::cout << "&y=" << &y << "\n";
std::cout << "&z=" << &z << "\n";
}
int main()
{
foo(10.1, 10.2, 10.3);
return 0;
}
Visual C++の実行結果:
(x, y, z)=(10.1, 10.2, 10.3) &x=010FFA08 &y=010FFA10 &z=010FFA18
使っているCPUでは、スタックは先に積んだ方がアドレスの高い方に保存されますので、z → y → x 順序でスタックに積まれていることが分かります。・・・①
gccの場合
実はubuntu(gcc)で同じ実験を行うと&x, &y, &zのアドレスは、上記と逆でx, y, zの順で高い方のアドレスへ割り当てられます。これは上記で述べたレジスタで引数が渡されたためです。
レジスタのままだとアドレスが割り当てられませんが、foo関数側でスタックへ保存されるためアドレスが割り当てられます。
このようにレジスタ経由で引数が渡された場合、その割り当てられるアドレスの順序は①で示したような順序にならない場合があります。
C言語と同じ仕組みを導入しているので、C++でもC言語と同じ仕組みの可変長引数を使えます。
しかし、可変長引数関数では、実引数の型と個数を適切に伝達する必要があり、それに失敗すると異常動作します。安易にプログラムするとセキュリティ上の脆弱性にもつながります。
例えば、x, y, zがdouble型変数の時に、int型変数を指定する”%d”で表示しようとするとおかしな値が表示されます。
#include <iostream>
#include <cstdio>
int main()
{
double x=10.1;
double y=10.2;
double z=10.3;
printf("(x, y, z)=(%f, %f, %f)\n", x, y, z);
printf("(x, y, z)=(%d, %d, %d)\n", x, y, z);
std::cout << "(x, y, z)=(" << x << ", " << y << ", " << z << ")\n";
return 0;
}
Visual C++の実行結果:
(x, y, z)=(10.100000, 10.200000, 10.300000) (x, y, z)=(858993459, 1076114227, 1717986918) (x, y, z)=(10.1, 10.2, 10.3)
対応を間違うと悲惨ですね。
C++11で導入された可変長引数テンプレート(Validac Templates)を使えば、可変長引数で、かつ、実引数の型を呼び出し側と関数側で合意してプログラムできますので、この問題を回避できます。
さて、そのような可変長引数を使いたいケースの典型的な例はprintf()シリーズと思います。ログ出力などで良く使います。
C++でもprintf()のように書式指定できるライブラリがあります。boost::formatです。これを使うとprintf()風の書式指定が可能です。しかも、書式指定を間違っても「デタラメ」にはなりません。また、セキュリティ上のリスクも最小限です。
しかし、boost::formatはC++11より以前に用意されているため、複数の項目を%で区切って表示するためちょっと使いづらいです。そこで、弊社のTheolizer®ではboost::formatとC++11の可変長引数テンプレートを用いて、よりprintf()に近づけた使い勝手のtheolizer::print()関数を用意してます。Theolizer®はGPLv3で無料公開してます。(以上、宣伝でした。)
第5回目の3.ローカル変数で説明したローカル変数は関数の中で定義された変数のことでした。第5回目で説明したようにローカル変数は関数内で定義され、その関数の外からアクセスすることはできません。
このように外部から隠蔽されている変数は、外部の想定外のルーチンが使ったり変更したりする心配がなく、確実に専有できているので安心して使えます。
このローカル変数も通常のものはスタック上に確保されます。(実引数同様レジスタに記録される場合もありますが、実引数と同じく振る舞い的にはスタック上と考えて問題ありません。)
早速実験です。
#include <iostream>
void foo(double x, double y, double z)
{
std::cout << "(x, y, z)=(" << x << ", " << y << ", " << z << ")\n";
std::cout << "&x=" << &x << "\n";
std::cout << "&y=" << &y << "\n";
std::cout << "&z=" << &z << "\n";
double volume=x*y*z;
double surface=(x*y + x*z + y*z)*2;
std::cout << "volume=" << volume << " &volume=" << &volume << "\n";
std::cout << "surface=" << surface << " &surface=" << &surface << "\n";
}
int main()
{
foo(10.1, 10.2, 10.3);
return 0;
}
Visual C++の実行結果:
(x, y, z)=(10.1, 10.2, 10.3) &x=00BEF774 &y=00BEF77C &z=00BEF784 volume=1061.11 &volume=00BEF760 surface=624.22 &surface=00BEF750
ちょっと見にくいのでアドレスを整理してみます。4バイト単位で記載します。
Visual C++はdouble型変数は8バイト使用します(PC用のgccも同じ)ので、下図のように割り当てられています。

このように実引数(x, y, z)の「上」に「戻り先」が積まれ、更にその上にローカル変数(surfaceとvolume)が積まれています。
基本型とポインタ型のローカル変数は、コンパイラは自動的に初期化しなくても良いと標準規格で規定されています。自動的に0初期化するコンパイラもあればしないコンパイラもあります。
例えば、gccは自動的に0で初期化するようですが、Visual C++は自動的には初期化しません。
いつ初期化され、いつ初期化されないかきちんと把握することも可能ですが、それなりに手間がかかります。そこで、基本型とポインタ型は常に初期化することが望ましいです。 どうしても初期化できない場合のみ(かなりレアです)、自動初期化されることを確認して自動的な初期化に頼りましょう。
自動的に初期化される時されない時
クラス(classやstruct)はオブジェクト生成時にコンストラクタが呼ばれますので、コンストラクタでキチンと初期化しておけば、初期化漏れは有りえません。
しかし、基本型は原則として自動的に初期化されません。ただし、C++11の文法と機能によると、「静的変数用メモリ(staticストレージ)」と「スレッド・ストレージ(本講座では解説していません)」に記録される変数は自動的にゼロで初期化されます。
そして、このような通常のローカル変数には寿命があります。定義された文で生成され、その文を含むブロックから抜けた時に破棄されます。
この点は良く覚えておいて下さい。「ポインタ」や「参照」で、破棄される前の変数のアドレスを記録し、元の変数が破棄された後でもそのアドレスをアクセスするプログラムをC++は書くことができます。しかし、破棄後の変数をアクセスすると何が起こるか全く分かりません。・・・②
ですので、引数や通常のローカル変数へのポインタや参照を使う場合はその寿命に注意して下さい。
ちょっと実験です。下記のプログラムを実行してみます。
error.cpp
#include <iostream>
int* foo()
{
int x=10;
std::cout << "foo() : x=" << x << "\n";
return &x;
}
int bar()
{
int y=20;
std::cout << "bar() : y=" << y << "\n";
return y;
}
int main()
{
int* x=foo();
int y=bar();
std::cout << "*x=" << *x << "\n";
std::cout << "y =" << y << "\n";
return 0;
}
CMakeLists.txt
project(error)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
endif()
add_executable(error error.cpp)
Visual C++の実行結果:
foo() : x=10 bar() : y=20 *x=10489911 y =20
gccの実行結果:
foo() : x=10 bar() : y=20 Segmentation fault (コアダンプ)
foo()関数はローカル変数xへのポインタを返却しています。ローカル変数xはfoo()終了時に破棄されますから、foo()から戻って来た時xへのポインタの指す先は破棄されています。この場合、元のxに割り当てられたスタック領域は別の関数のローカル変数として使われますので、xへ設定した値が他の値に変わってしまったり、不正アクセスとしてプログラムが異常終了(コアダンプ)してしまったりします。
なお、このケースではコンパイラが検出できる危険な操作なのでコンパイル時に警告してくれます。
そのような問題を回避するには、bar()関数のようにポインタを返却するのではなく、値をコピーして返却します。(大きなオブジェクトを返却する場合、コピー負荷が気になりますが、最近のコンパイラは最適化によりコピーしないで返却する仕組みを実装しているものが多いです。)
寿命が短い変数にメリットはあるのか?
このような振る舞いをみていると寿命の短い変数は害あって益なしのようにも見えますね。
しかし、寿命が短い変数はメンテナンスしやすいプログラムを開発する際に有用です。
既に使っていない変数がいつまでも生きていた場合、その変数の値が書き換えられたり、使われたりする可能性が残ります。
適切に設定されていないことを忘れてアクセスする、知らずに他の人がアクセスしてしまうなどは「あってはならないこと」なのですが、良くあります。全ての変数について使ってよい場面を正確にドキュメント化し、それを確実に伝達することは現実問題不可能に近いからです。
そこで、プログラミング言語の「変数を使える場所を限定する」機能を利用して、使うべきでない場所で変数を使えないように記述し、関係者へ確実に伝達します。これにより、より安全なプログラムを開発できるようになるのです。
そこに開いている落とし穴が上述の②なのです。
通常のローカル変数より「寿命」が長いローカル変数があります。staticなローカル変数です。
先に述べたように非staticなローカル変数の寿命は、それが定義されたブロック内だけです。
- 定義された時に生成され、
- 定義されたブロックから抜けた時に破棄されます。
それに対してstaticなローカル変数はプログラムが終了するまで破棄されません。
- プログラムの開始時に生成されます。
初期化付きで宣言された場合、最初に定義文を実行した時に初期化され、以降定義文を実行しても再度初期化されることはありません。 - プログラムが終了するまで破棄されません。
staticなローカル変数は定義する時に、型名の前か後ろでstatic修飾子を次のように書きます。
static int foo; int static bar;
(前者は良く見ますが、後者はあまり見ないです。staticであることを見落とさない工夫と思います。)
では振る舞いを実際に見てみましょう。
static-local.cpp
#include <iostream>
int foo()
{
int normal_variable=10;
++normal_variable;
return normal_variable;
}
int bar()
{
static int static_variable=10;
++static_variable;
return static_variable;
}
int main()
{
std::cout << "foo()=" << foo() << "\n";
std::cout << "foo()=" << foo() << "\n";
std::cout << "foo()=" << foo() << "\n";
std::cout << "bar()=" << bar() << "\n";
std::cout << "bar()=" << bar() << "\n";
std::cout << "bar()=" << bar() << "\n";
return 0;
}
CMakeLists.txt
project(static-local)
if(MSVC)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /W4 /EHsc")
else()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -std=c++11")
endif()
add_executable(static-local static-local.cpp)
実行結果(Visual C++, gcc共に同じ):
foo()=11 foo()=11 foo()=11 bar()=11 bar()=12 bar()=13
foo()関数のnormal_valiableは通常の非staticなローカル変数なので定義文が実行されるたびに生成され、初期化されます。従って、foo()関数が呼び出される度に10へ初期化されるので、常に11が返却されています。
bar()関数のstatic_variableはstaticなローカル変数ですのでfoo()関数とは動作が異なります。
- 最初に定義文を実行した時に10で初期化され、次の文でインクリメントされていますので、最初にbar()関数から抜ける時は11が返却されます。
- そのままstatic_variableは維持されますので、再度bar()関数が呼ばれた時も11のままです。そして、定義文を再度実行しても再度初期化されませんので11のまま、次の文でインクリメントされ12となり、12が返却されます。
- その次の呼び出しも同様に動作し13が返却されます。
このようにstaticなローカル変数は通常のローカル変数とは振る舞いが異なります。
しかし、定義されている関数やブロックの外からアクセスできないと言う点は通常のローカル変数と同じです。
さて、このstaticなローカル変数をスタック上に保存した場合、関数が終了した時に破棄されてしまいます。スタックは関数を実行中だけメモリを専有するので同時に実行しない他の関数とメモリを共有できる優れた仕組みなのですが、関数から抜けても維持したい変数を記録できません。
では、どこに記録されるのか? おっとここで時間です。次回解説します。
今回は、関数の実引数の値渡しはスタックを用いること、非staticなローカル変数も同じくスタックに記録されることを説明しました。特に重要なことは、このスタックの使い方です。引数と変数がスタックに積まれ、関数の終了時に自動的に(強制的に)解放されます。
解放後に間違ってアクセスしないことは非常に重要ですので肝に命じて下さいね。
また、staticなローカル変数の振る舞いについて触れましたが、仕組みは説明していません。
仕組みはグローバル変数と同じ仕組みですので、次回グローバル変数と共に解説します。
それでは、次回は分割コンパイルとグローバル変数とstatic記憶領域(静的変数用メモリ)について解説する予定です。お楽しみに。
